Research
Robot Intelligence
▶ AML: An AI Foundation Model-based Agent for Language-Driven Zero-Shot Object Navigation
Objective
· 자연어로 주어진 목표 물체를 미지의 환경에서 시각 정보만으로 탐색하는 L-ZSON 작업 수행
· 목표 물체에 대한 정교한 시각적 그라운딩과 공간적 맥락 이해 능력 필요
· 효율적인 탐험 행동 결정을 위해 시각 인식–맵 생성–언어 추론을 통합한 새로운 에이전트 모델 요구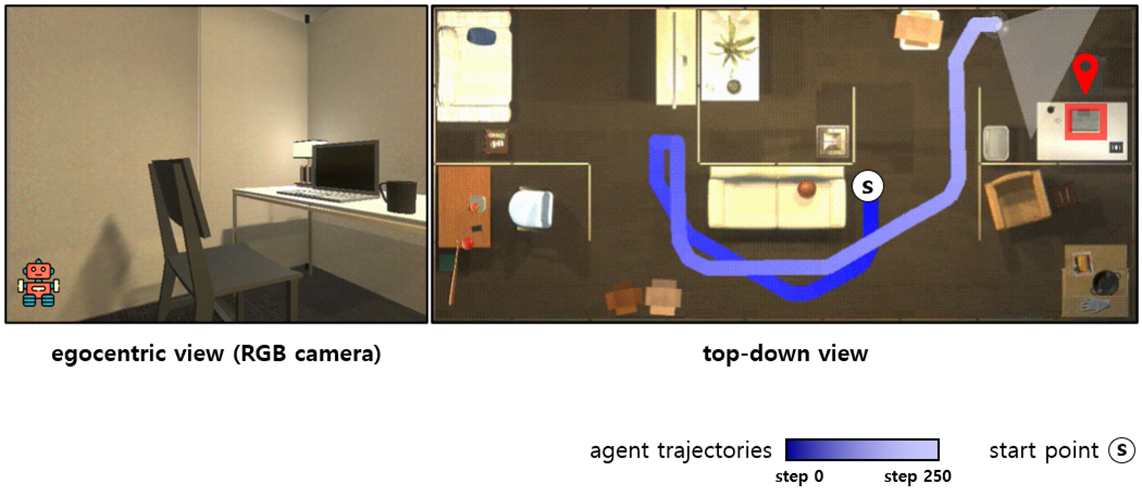
Approach
· GLEE + GLIP 기반의 시각 인식 모듈로 목표 객체와 환경 요소를 정확히 탐지
· 그래프 기반 semantic context map으로 방·가구·아이템의 공간 관계를 구조적으로 표현
· LLM에 환경 맥락을 제공해 목표 방 추론 후 연관 물체 추론으로 이어지는 2단계 reasoning
· PSL 기반의 확률적 frontier 선택 정책으로 효율적인 탐색 경로 결정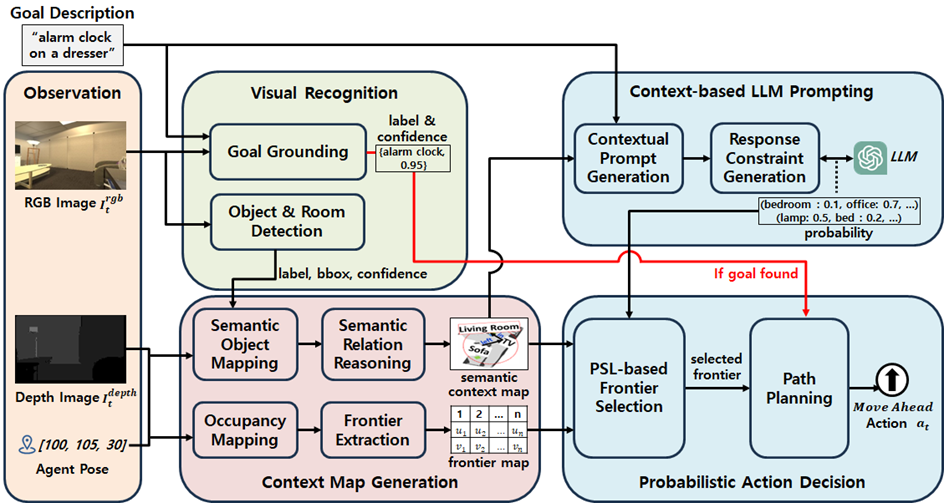
▶ Multimodal Mapping and Reward Function Design for Multi-Object Visual Navigation
Objective
· 다중 물체 시각적 이동 탐색(MultiON)은 로봇이 다수의 목표 물체까지 순서에 맞게 도달하기 위해 시각적 정보만을 활용하여 이동 행동을 계획 및 수행하는 작업
· 색상, 모양 등 물체 속성들에 대한 언어적 묘사로 주어지는 목표 물체들을 입력 영상에서 정확하게 식별해내기 위한 방식 요구
· 입력 영상에서 추출하는 불완전하고 불확실한 지역적 공간 맥락정보를 효과적으로 전역적 지도에 등록하는 방식 요구
· 에이전트의 작업 성공률과 효율성을 높이기 위한 강화학습(reinforcement learning)의 보상함수 설계 방식 요구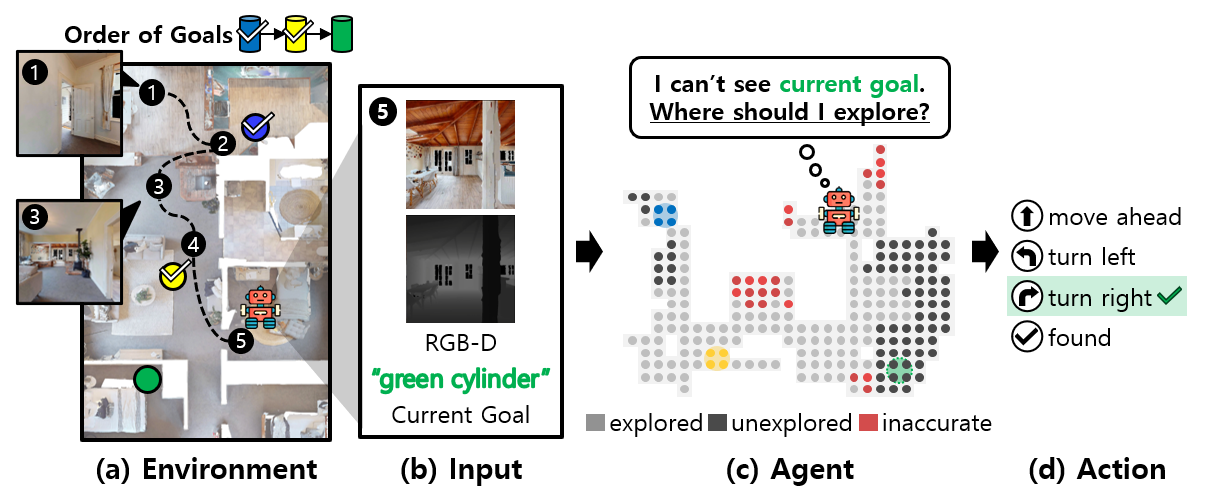
Approach
· 다중 물체 시각적 이동 탐색(MultiON) 작업을 위한 심층 신경망 에이전트 모델 G2M3(Goal Grounding and Multimodal Mapping for MultiON) 제안
· 자연어로 색상 및 모양이 묘사된 목표를 입력 영상에서 제로-샷(zero-shot) 방식으로 탐지하기 위해, 비쥬얼 그라운딩(visual grounding) 모델인 Grounding-DINO 이용
· 입력 영상에서 추출하는 부분적이고 불확실한 지역적 맥락정보를 효과적으로 지도에 등록하기 위해, 베이즈 정리(Bayes theorem) 기반의 사후 확률 이용
· 미지의 환경에 대한 빠른 전역적 지도의 확장과 정확도 증진을 위한 내적 보상함수 사용
· 3차원 시뮬레이터 Habitat와 벤치마크 실내 환경 데이터 집합 Matterport3D를 이용하여 다양한 실험들을 수행하고, 제안 모델의 우수성 입증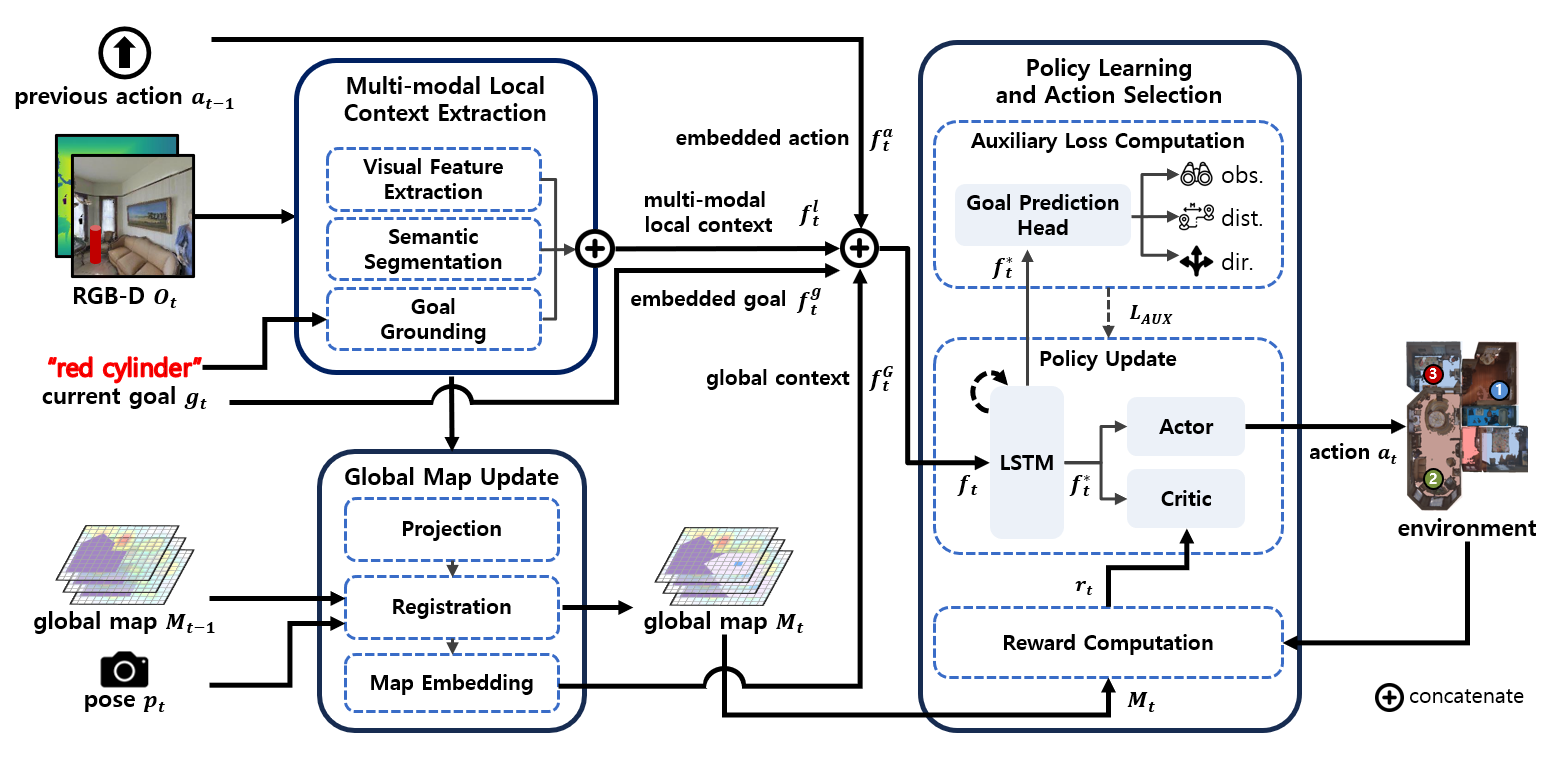
▶ Visual Context Embedding and Deadlock Processing for Target-driven Visual Navigation
Objective
· 목표 기반 시각적 이동 작업(Target-driven Visual Navigation)이란 로봇 에이전트가 실시간 입력 영상 정보에 의존하여 정해진 목표를 찾아가는 작업
· 성공적인 시각적 이동 작업을 위해서는 실시간 입력 영상들로부터 정확하고, 심도있게 현재 상황을 파악하는 시각적 맥락 이해 능력이 요구됨
· 이해한 시각적 맥락을 바탕으로 목표 물체까지 효율적으로 이동하기 위해서는 최적의 행동 정책 계획 또는 학습 능력이 요구됨
· 이러한 요구사항들을 반영하여, 시각적 이동 작업을 위한 에이전트 모델을 개발
Approach
· 시각적 이동 작업을 위한 심층 신경망 기반 에이전트 모델 VCENet(Visual Context Embedding Network)를 제안
· 시각적 맥락 네트워크(Visual Context Network, VCN)를 통해 에이전트 중심의 RGB-D 입력 영상을 기반으로 현재 작업상황을 이해
· VCN은 배경 장면에 대한 맥락 이해를 위한 배경 맥락 임베딩(background context embedding) 서브 네트워크와 물체들 간의 관계 이해를 위한 물체 관계 맥락 임베딩(object relation context embedding) 서브 네트워크로 구성
· 작업 중 발생하는 교착상태(deadlock)에 대응 가능한 정책 학습을 위해 2가지 방법 제안
· (1) 교착상태 회피 및 복구를 위한 새로운 보상 함수 제시 (2) 교착상태 복구를 위한 적응적 모방학습(adaptive imitation learning) 제시
· 3차원 시뮬레이터 AI2-THOR의 가상 실내 환경을 이용하여 다양한 실험들을 수행하고, 제안모델의 효과 입증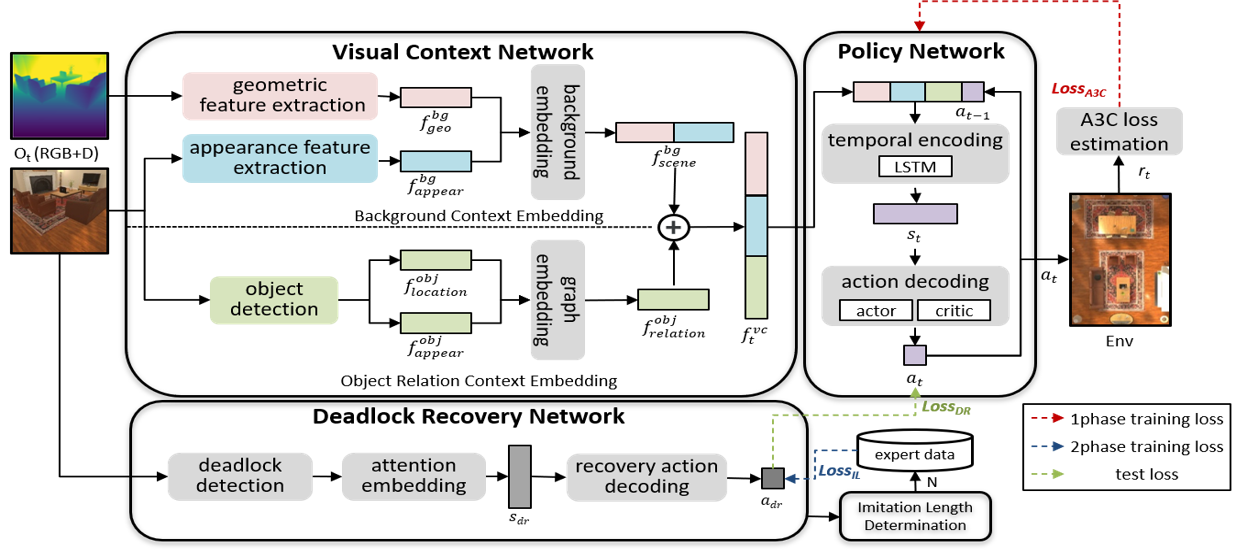
▶ Transformer-based On-Offline Hybrid Reinforcement Learning for Locomotion Tasks
Objective
· 로봇 보행(robot locomotion)은 다 관절 로봇이 실시간 자율제어를 통해 보행하는 작업
· 다 관절 로봇의 보행을 위한 강화 학습은 매우 큰 연속 상태 및 행동 공간(continuous state & action space)을 가짐
· 온라인 강화 학습(online RL)은 많은 시행 착오(trial and error)와 매우 긴 학습 시간(long training time)을 요구
· 오프라인 강화 학습(offline RL)은 학습 가능한 행동 정책이 미리 수집된 오프라인 데이터 집합(offline dataset)에 한정됨
· 기존의 온라인 및 오프라인 강화 학습의 한계성을 극복할 수 있는 새로운 강화 학습 프레임워크(RL framework) 제시
· 긴 작업 수행동안 과거 상태와 행동(previous states and actions)을 효과적으로 활용할 수 있는 정책 신경망(policy network) 개발
· 학습의 효율성을 향상을 위한 데이터 샘플링 전략(data sampling strategy) 개발
Approach
· 오프라인 데이터 집합과 학습자 자신의 온라인 경험 데이터을 함께 학습에 이용 가능한 복합 강화 학습 프레임워크(Hybrid RL framework)인 TO2HRL을 제시
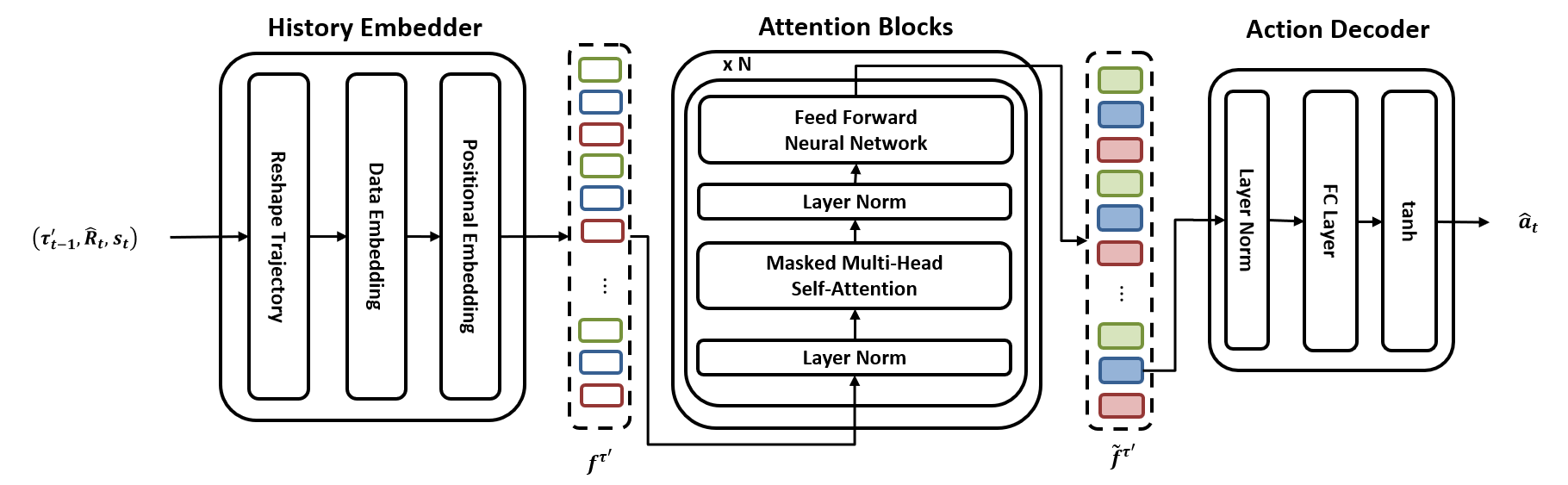
· Transformer 기반의 Policy Transformer를 정책 신경망으로 채용, 과거 상태와 행동들에 대한 정책의 장기 의존성(long-term dependency) 문제를 해결
· Policy Transformer는 셀프 어텐션 계층(self-attention layer)들을 포함한 Transformer의 디코더 블록(decoder block)을 이용해 구현
· 안정적인 보행 거리를 토대로 보행 진도를 측정, 학습 효율성 향상을 위한 새로운 진도 기반 우선 순위 샘플링 전략(progress-based priority sampling strategy)을 제시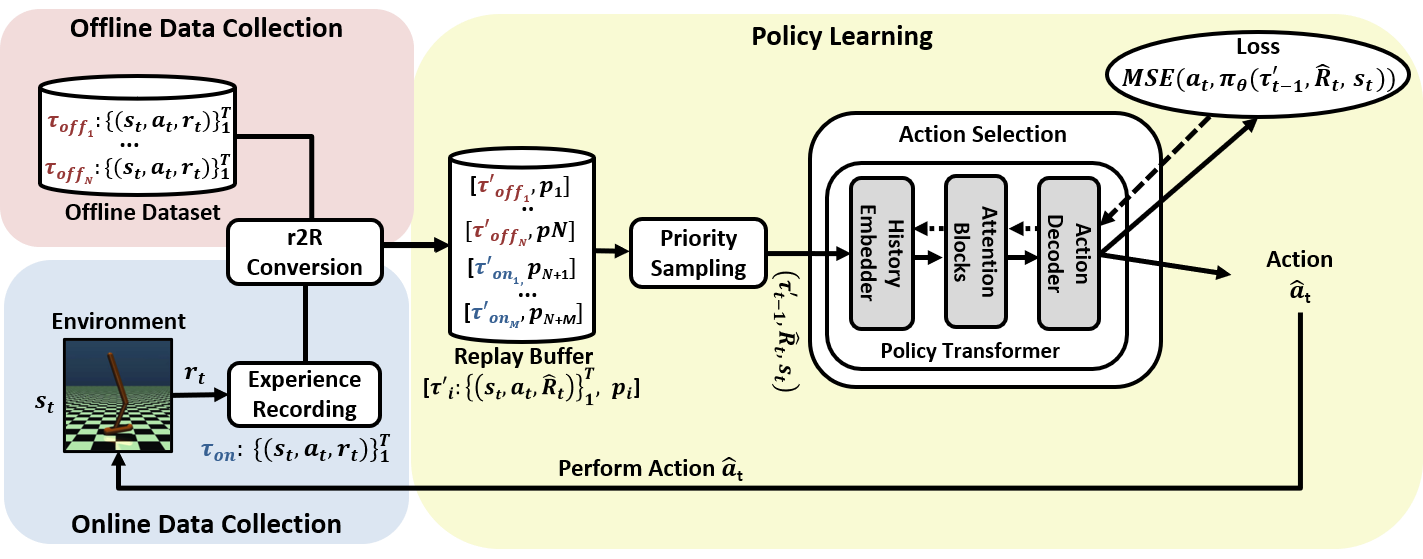
▶ Task Policy Learner for Multi-Robot Manufacturing Logistics
Objective
· 제조/물류 환경에서의 효과적인 다중 로봇 협업을 위해서는 각 로봇이 수행할 작업의 안전성/효율성(safety/efficiency) 예측을 위한 작업 정책 학습이 필요
· 실무 제조/물류 환경에서는 학습된 정책의 해석 가능성(interpretability)과 일반화 능력(generality)이 특별히 요구됨
· 빠르게 변화하는 다중 로봇 작업 환경에서 각 작업의 올바른 안전성/효율성 예측을 위해서는 다양한 시-공간적 맥락(spatio-temporal context) 정보와 실시간 예측(real-time prediction)이 요구됨
· 이러한 요구사항들을 충분히 반영하여, 작업의 안전성/효율성 예측을 위한 작업 정책 학습기(Task Policy Learner, TPL)를 개발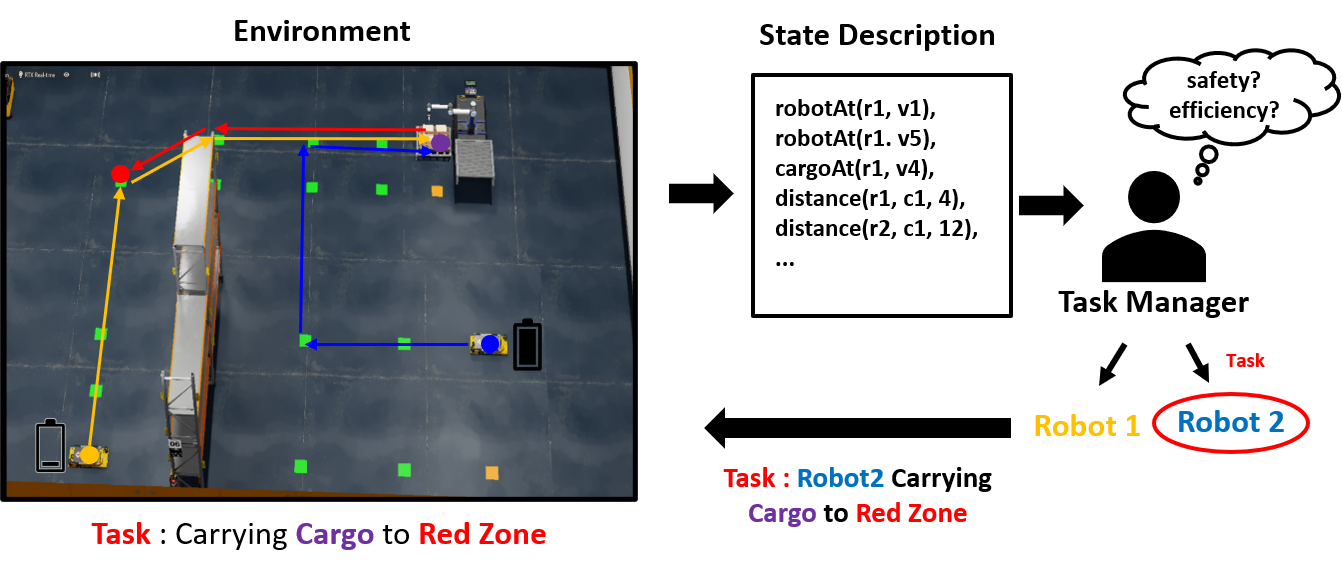
Approach
· 심층 관계형 강화학습(Deep Relational Reinforcement Learning) 기반의 새로운 작업 정책 학습기를 제안
· 제안하는 TPL은 특정 로봇에 할당될 작업의 실시간 안전성/효율성 예측을 위해, 심층 관계형 강화학습을 이용한 논리 형태의 정책 규칙들을 학습함
· 안전성/효율성에 관한 정책 규칙 학습은 2단계(two phases)로 진행
· 정책 파라미터 추론 단계(policy parameter reasoning phase) : 환경에 관한 관측 값들로부터 함수 기반 추론기를 거쳐 다양한 정책 파라미터들의 값을 추론
· 정책 규칙 학습 단계(policy rule learning phase) : 추론된 정책 파라미터들의 값을 토대로, 관계형 강화학습 엔진인 dNL-RRL을 적용하여 정책 규칙들을 학습
· 정책 규칙 학습의 효율성 향상을 위해, 영역-고유 지식(domain-specific knowledge)들의 효과적인 활용 방법 제시
· NVIDA Isaac 시뮬레이터를 이용한 다양한 실험들을 통해, TPL이 학습한 안전성/효율성 정책 규칙들을 검증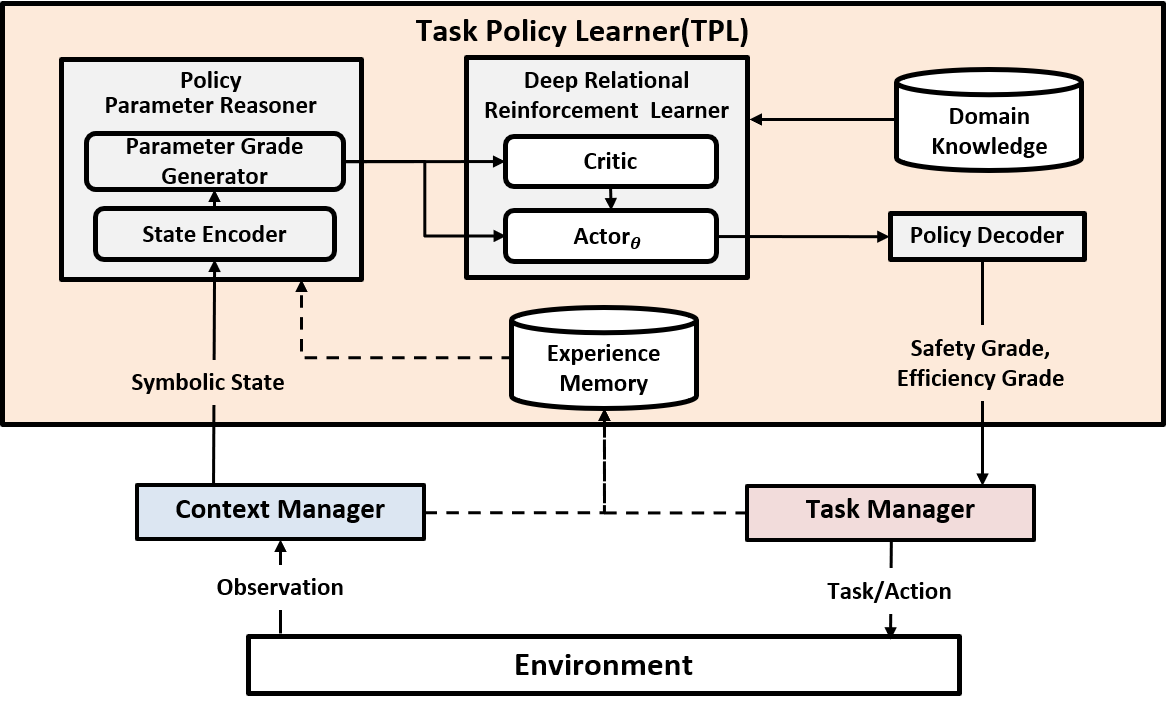
▶ Development of Manipulation Technologies in Social Contexts for Human-Care Service Robots
Objective
· 가정을 포함한 실내 환경에서, 물체가 갖는 기능적 이해 및 사회적 조작 방식의 이해
· 서비스 로봇의 조작 지능 기술 개발을 통한 휴먼케어 서비스 제공
· 목표 작업 : 냉장고 안의 겹쳐 있는 물건을 찾아 꺼내오기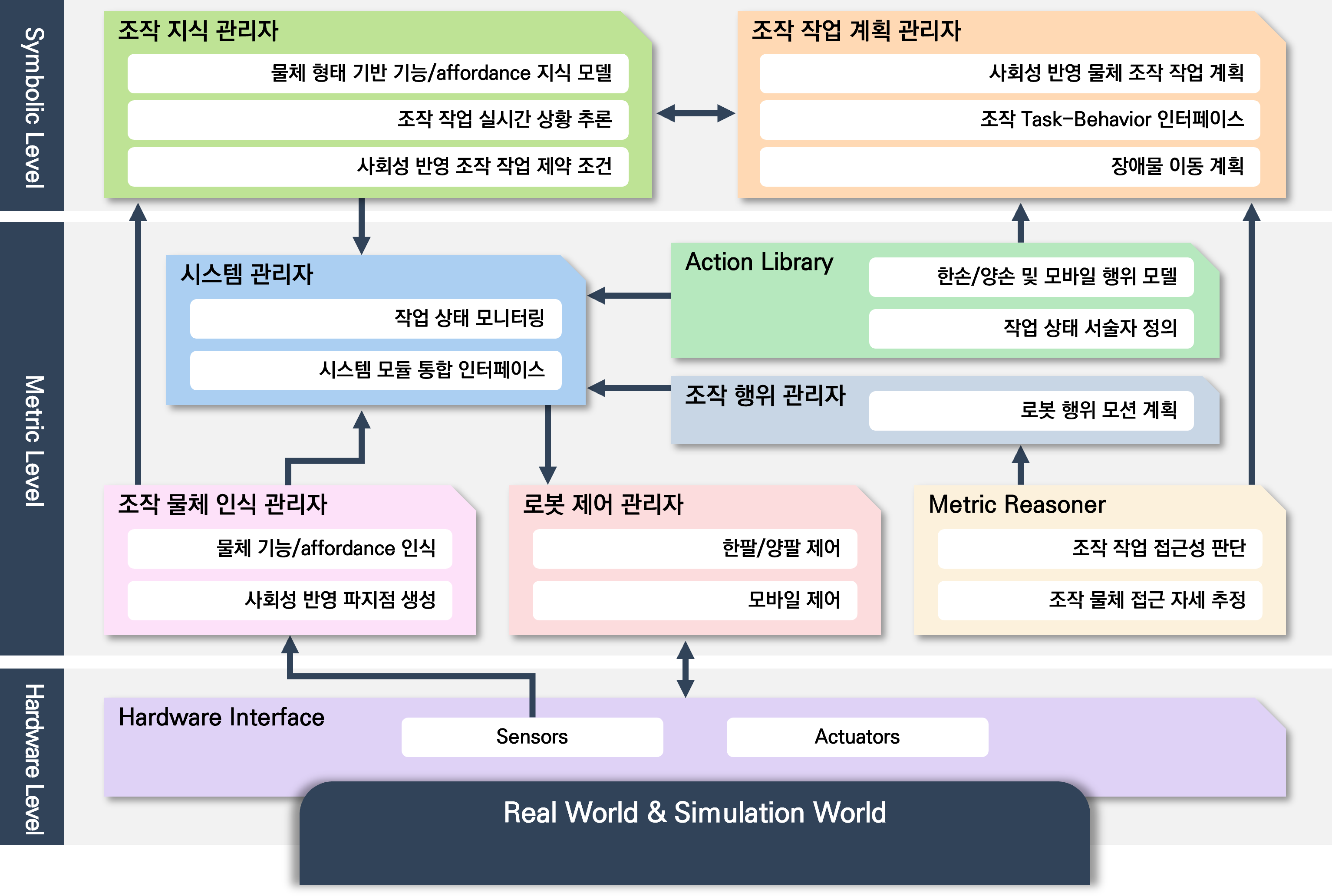
Approach
· 복잡환경에서 다양한 물체 및 환경에대한 인식(perception) 수행
· 조작 작업을 위한 물체의 어포던스(affordance)에 관한 고수준의 상황 추론(context reasoning)
· 상황 추론을 통한 작업 계획 수립(task planning) 및 로봇 매니퓰레이터(manipualtor) 제어
▶ Manipulation Service Development with Humanoid Robot
Objective
· Hubo 로봇과 휴먼 스케일(human-scale)의 물체들이 존재하는 편의점 환경에서 로봇 지능 체계의 실증적 검증
· 목표 작업 1: 상품 주문 시 진열대 또는 보관대에 있는 상품을 제공
· 목표 작업 2: 진열대에 상품이 비어 있을 경우 보관대에서 상품을 가져와 보충
Approach
· 인식 정보를 실시간으로 지식화하고 고수준의 작업 상태 서술자(task state predicate)들을 추론 및 갱신
· 고수준의 작업 상태 서술자로부터 추상적 작업 계획(abstract task plan)을 생성
· 추상적 작업 계획의 모션-실현 가능성(motion-feasibility)을 검증하고 이를 실행
· 모션-실현 가능한 작업 계획 생성 또는 실행 실패 시 재계획(replanning) 실시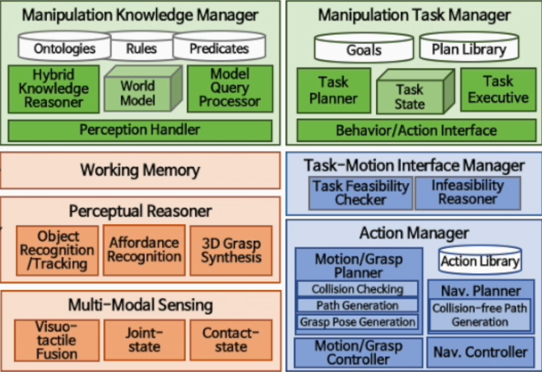
Application

▶ Hybrid Imitation Learning for Robotic Manipulation Task
Objective
· 다 자유도 로봇 팔(multi-DOF robot arm)의 물체 조작 작업(objective manipulation tasks)을 위한 혼합 학습(hybrid learning) 기술 연구
· 연속 상태-행동 공간(continuous state- action space)에서 로봇 행동 정책(policy) 학습을 위해 효율적인 학습 방법 요구
· 효과적인 로봇 조작 작업 학습을 위해 종래의 행위 복제(behavioral cloning)과 상태 경로 복제(state trajectory cloning)의 한계를 극복하기 위한 방법 요구
Approach
· 종래의 모방 학습 방법들의 한계를 상호 보완하기 위한 혼합 모방 학습 방법 설계
· 행위 복제와 다이나믹스 모델(dynamis model)을 이용한 상태 경로 복제를 혼합
· 이종 손실 함수(heterogeneous loss function) 결합을 통한 두 학습 방법의 혼용
· 행위 복제의 학습 수렴도(learning convergence)에 따라 두 손실 함수의 가중 비율(importance rate) 자동 조정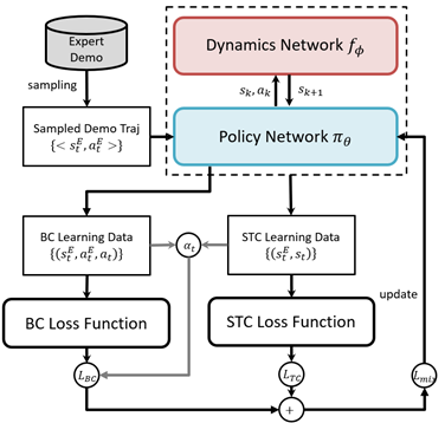
▶ AugGAIL: Generative Adversarial Imitation Learning for Robotic Manipulation Tasks
Objective
· 다 자유도 로봇 팔(multi-DOF robot arm)의 물체 조작 작업(objective manipulation tasks)을 위한 모방 학습(imitation learning) 기술 연구
· 연속 상태-행동 공간(continuous state- action space)에서 양질의 행동 정책(policy)을 효율적으로 배우기 위해
강화 학습(reinforcement learning)과 모방 학습(imitation learning)이 결합된 학습 방법 요구
· 효과적인 로봇 조작 작업 학습을 위해 종래의 GAIL 학습 프레임워크의 한계를 극복하기 위한 방법들 요구
Approach
· GAIL 기반의 모방 학습 프레임워크 AugGAIL 설계
· PPO(Proximal Policy Optimization) 알고리즘 적용
· 보상 함수(reward function) 확장
· 판별자 네트워크(discriminator network) 학습용 데이터 샘플링 전략
· 행위 복제 사전 학습(behavioral cloning pretraining)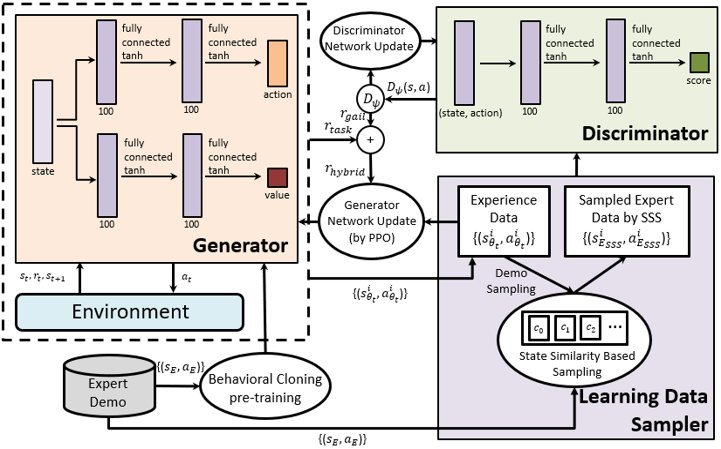
▶ Constraint Satisfaction for Motion-Feasibility Checking
Objective
· 인공지능 분야의 작업 계획 생성(task planning)과 로봇공학 분야의 모션 계획 생성(motion planning)을 결합하여 모션-실현 가능한 작업 계획(motion-feasible task plan)을 생성하는 작업-모션 계획의 연계(task and motion planning) 관한 연구
· 작업-모션 계획의 전체적인 연계 과정 중에서, 작업 계획 스켈레톤(task plan skeleton)이 주어졌을 때 이 작업 스켈레톤의 모션-실현 가능성(motion-feasibility)을 검증하는 것에 초점을 맞춤
· 모션 실현 가능성 검증 문제를 제약 충족 문제(constraint satisfaction problem)로 모델링하고 해결하는 방법을 제안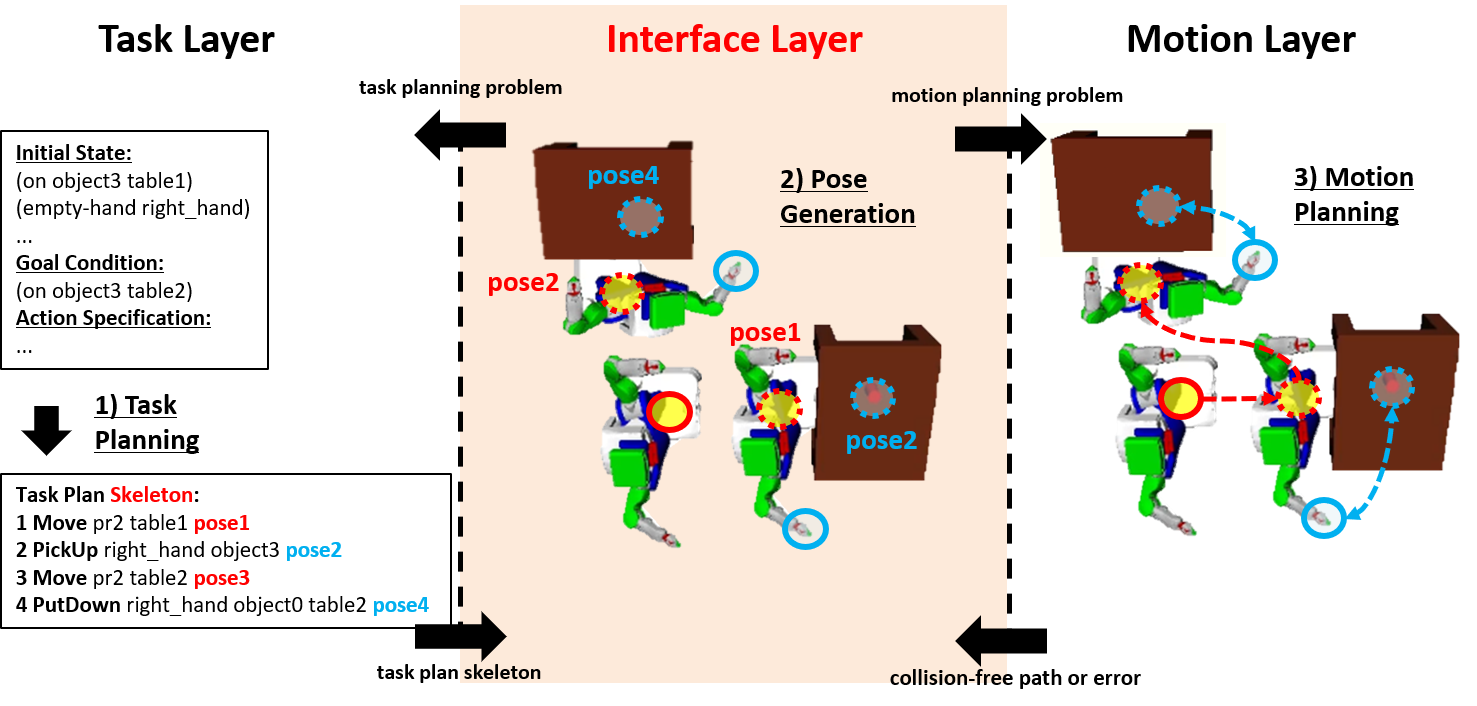
Approach
· 작업 계획 스켈레톤의 값이 할당된 인자(bound parameter)와 그렇지 않은 인자(unbound parameter)가 갖는 의미(semantic)를 발견하고 이를 이용한 포즈 후보군을 생성하는 방법 설계
· 동작들 간의 의존성(inter-action dependency)과 각 동작 내 의존성(intra-action dependency)과 같은 영역 특수적 지식을 발견하고 이를 이용한 정렬 휴리스틱을 설계
· 모션 실현 가능성 검증에 효과적인 특수 목적(special-purpose) 제약 전파와 이를 수반하는 탐색 전략을 설계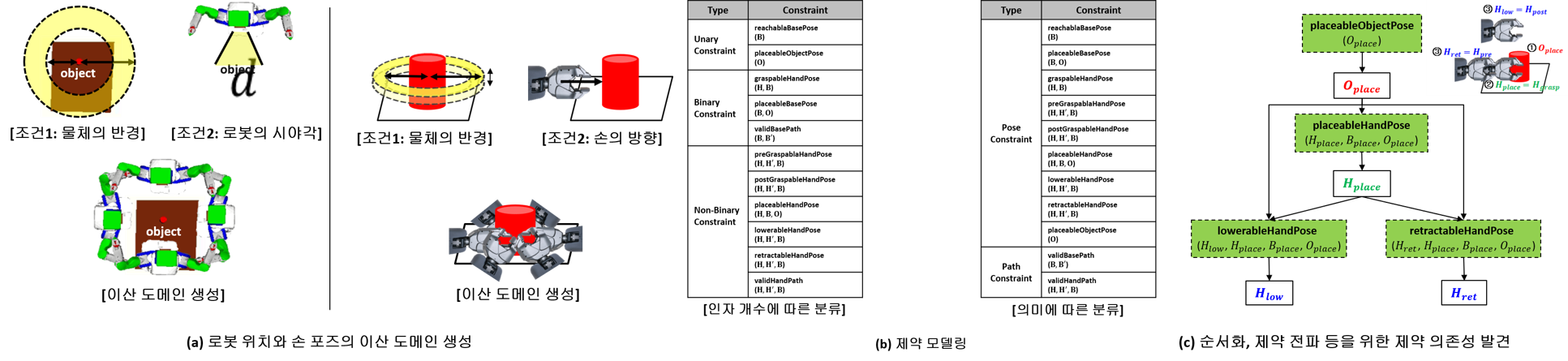
Application

▶ Generating Robot Task Plans from Action Ontology
Objective
· 지능형 서비스 로봇이 길찾기(navigation), 조작(manipulation) 등의 행동(behavior)들을 수행하기 위해 실행 가능한 형태의 제어 모델(control model)을 자동으로 생성하는 방법에 관한 연구
· 로봇이 스스로 제어 모델을 얻어내기 위한 방법으로 개념적 행위 모델(conceptual action model)로부터 작업 계획(task plan)을 변형(translation)하는 것이 일반적임
· 온톨로지(ontology) 기반의 개념적 행위 모델을 설계하고 개념적 행위 모델로부터 작업 계획을 자동으로 생성해내는 방법을 제안
Approach
· 시맨틱 웹(semantic web) 온톨로지 언어인 OWL을 기반으로 행위들의 클래스 계층(class hierarchy)을 정의
· 행위들의 입력 매개변수(input parameter)와 실행 순서(ordering), 그리고 전-조건(precondition), 지속 조건(durative condition), 효과(effect) 등의 행위 조건들을 표현할 수 있는 다양한 성질(property)들을 정의
· OWL 언어로 작성된 개념적 행위 모델을 에이전트 계획 언어인 JPL(JAM-agent Plan Language)의 계획 라이브러리(Plan Library)로 변형(Translation)하고 JPL 계획 생성기(JPL Planner)를 이용하여 Task Plan을 생성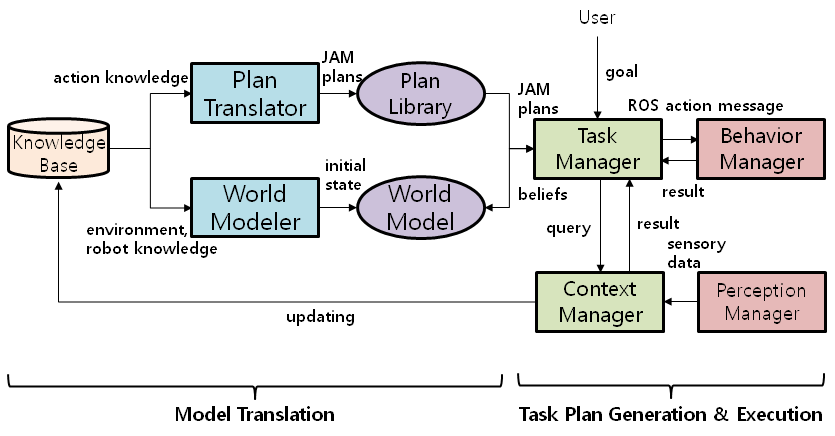
Application
▶ Object Modeling for Robot Manipulation
Objective
· 지식 체계 기반의 로봇 물체 조작(robot manipulation)을 위해 물체 카테고리(category), 속성(attribute), 부품(part), 어포던스(affordance), 파지점(grasping point) 등을 표현하는 물체 지식 모델링에 관한 연구
· 물체 지식은 작업 계획 생성(task planning)뿐만 아니라 모션 계획 생성(motion planning)에서도 응용됨에 따라 매우 구체적인 수준으로 확장되어야 함
· 특히, 물체 조작의 정밀도(precision)를 높이기 위해서는 물체 어포던스, 파지점 등은 부품 단위로 모델링이 가능해야 함
Approach
· 온톨로지 기반(ontology-based)의 물체 모델을 구축하기 위해서 가장 먼저 물체들의 개념(concept)을 표현하기 위한 클래스(class)들과 이들 간의 계층(hierarchy)을 구축하고 물체 속성과 부품을 표현할 수 있는 기본적인 성질(property)들을 정의
· 물체에 대한 통상적인 어포던스 지식 뿐만 아니라 물체의 각 부품에 대한 구체적인 어포던스 지식을 표현할 수 있도록 다양한 성질들을 정의
· 다지(multiple fingers)를 가지는 로봇의 손을 대상으로 손의 유형(type), 자세(posture), 그리고 각 손가락 끝점(fingertip)이 물체의 각 부품에 맞닿는 파지점을 표현 가능하도록 다양한 성질들을 정의
· 또한, 동적으로 자세가 변하는 물체와 로봇 팔의 자유도 한계를 고려하여 다양한 자세의 여러 파지점 후보들을 만들 수 있도록 설계
Application

▶ Spatio-Temporal Context Query Processing
Objective
· 3차원 물체들의 개별 인식 정보로부터 현재의 시-공간 상황 지식(spatio-temporal context knowledge)뿐만 아니라 과거의 특정 시간 시점 또는 구간과 현재와 과거를 복합적으로 조회
· 실시간으로 스트림(stream) 형태로 빠른 속도로 입력되는 인식 정보로부터 효율적인 질의 처리 방식 요구
· 높은 시간 의존성을 가지는 서비스 로봇의 상황 정보를 조회할 수 있는 질의 처리기(query processor)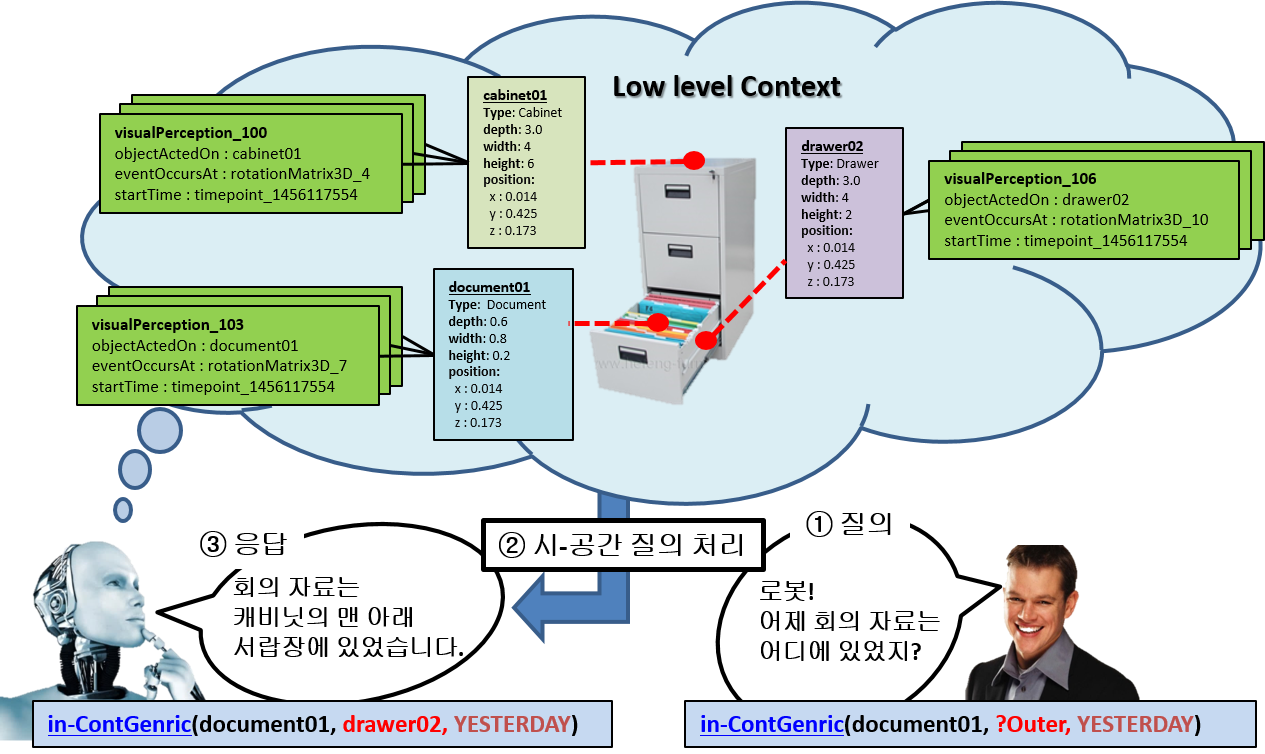
Approach
· Allen 간격 대수 이론에 기초한 시간 연산자를 포함하고 있는 상황 질의 언어(context query language) 설계
· 시-공간 색인(spatio-temporal index)을 기반으로 메모리 접근 속도를 향상시켜 질의 처리 가속화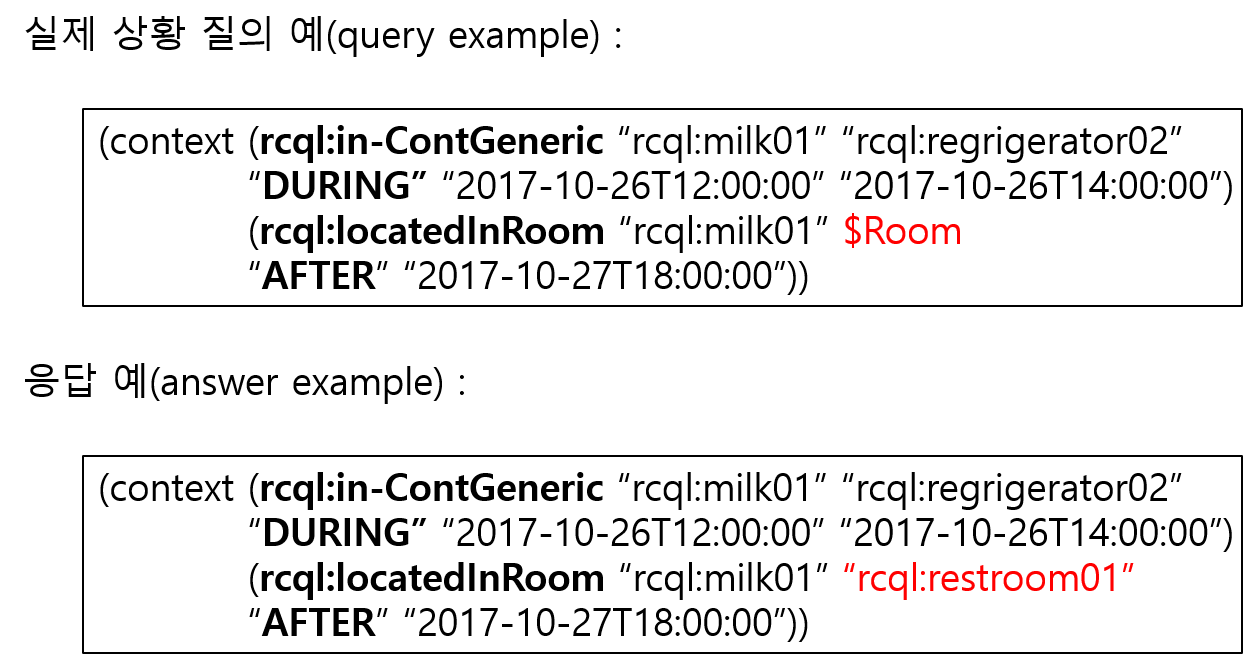
Application

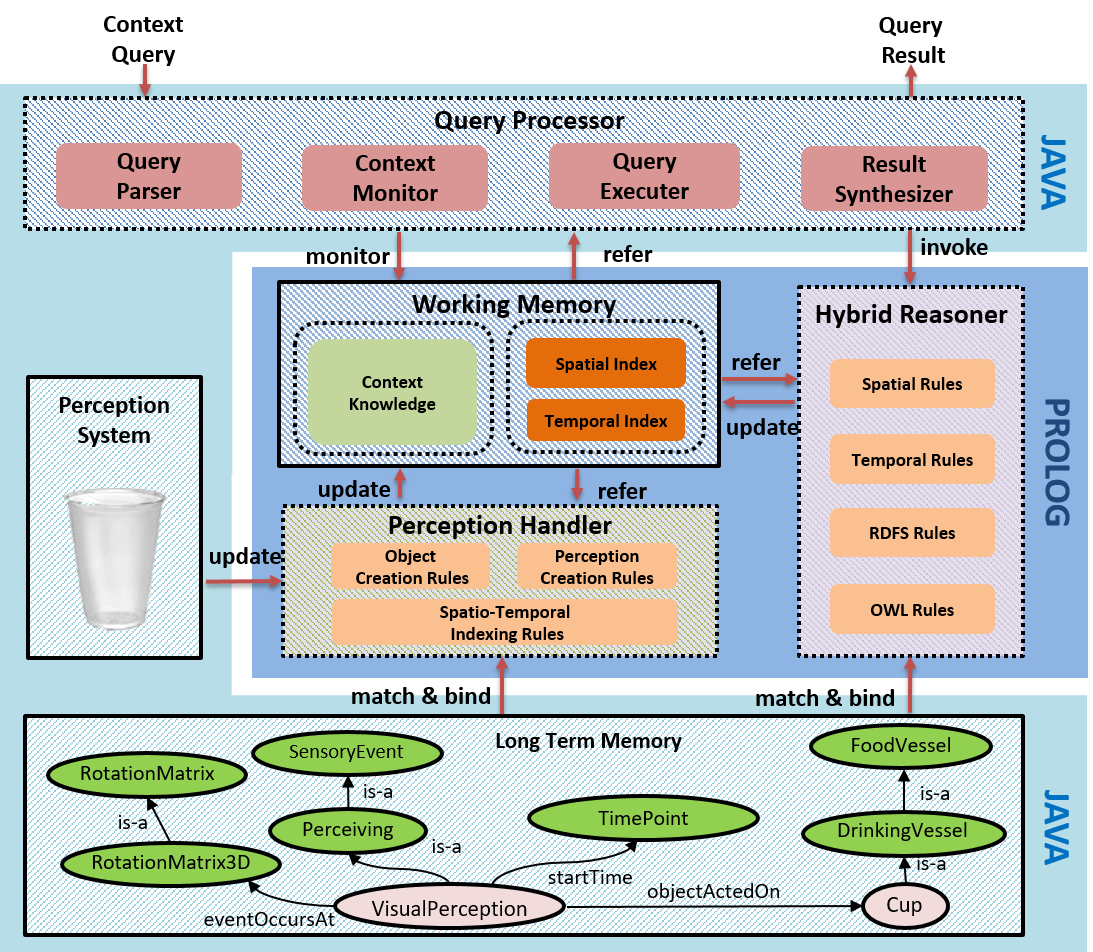
▶ Dynamic Context Management
Objective
· 동적으로 변화하는 주변 환경에 대한 올바른 상황 인식(context awareness)과 상황 이해(context understanding) 능력
· 실시간으로 입력되는 다양한 센서 데이터로부터 신속히 의사 결정(decision making)에 필요한 고 수준의 상황 지식(high-level context knowledge)을 생성
· 실시간성을 만족할 수 있는 시-공간 추론(spatio-temporal reasoning)
Approach
· 다양한 종류의 센서와 인식 시스템들을 통합적으로 이용하기 위해, 이들과의 동기 인터페이스와 비-동기 인터페이스를 함께 제공
· 체계적인 상황 지식 생성을 위해 상황 지식 표현의 근간이 되는 개념 계층(concept hierarchy)과 관계 계층(property hierarchy)을 하나의 포괄적인 온톨로지(ontology)로 정의하고 이용
· 온톨로지 지식은 설명 논리(Description Logic, DL) 기반의 온톨로지 언어인 RDF와 OWL로 표현, 반면에 사물과 개념, 그리고 그들 간의 관계들이 만족해야 하는 다양한 공리(axiom)와 추론 규칙(reasoning rule)들은 표현력(expressive power)과 추론의 효율성(reasoning efficiency)을 고려하여 Horn 논리 기반의 Prolog 규칙들로 표현
· 상황 지식 관리와 추론의 효율성을 극대화하기 위해, 저 수준의 상황 지식은 센서 및 인식 데이터가 입력될 때마다 실시간적으로 생성, 반면에 고 수준의 상황 지식은 의사 결정 모듈에서 요구가 있을 때만 후향 시-공간 추론(on-demand, backward, spatio-temporal reasoning)을 통해 생성되도록 알고리즘을 설계
▶ Deep Reinforcement Learning for Manipulation Tasks
Objective
· 다 자유도 로봇 팔(multi-DOF robot arm) 기반의 조작 작업(manipulation task)을 위한 심층 강화 학습(deep reinforcement learning) 기술 연구
· 로봇(Kinova Jaco Arm 6-DOF & Hand 3-DOF), 조작 작업(Catch, Pick & Place), 조작 물체(cube, sphere)
· 연속 상태 공간(continuous state space)
· 연속 행동/제어 공간(continuous action/control space)
· 실시간 제약(real-time constraint)
· 높은 학습 데이터 효율성(data efficiency) 요구
Approach
· Actor-Critic Policy Gradient 심층 강화 학습 적용
· 종래 Policy Gradient 알고리즘들의 낮은 데이터 효율성(low data efficiency)과 성능 불안정성(unreliable performance)을 극복
· 적응형 KL 기반 PPO(Proximal Policy Optimization) 알고리즘 적용
· 정책 성능의 하한선(low bound of performance)을 새로운 목적 함수로 채용
· 빠르고 안정적인 정책 학습 보장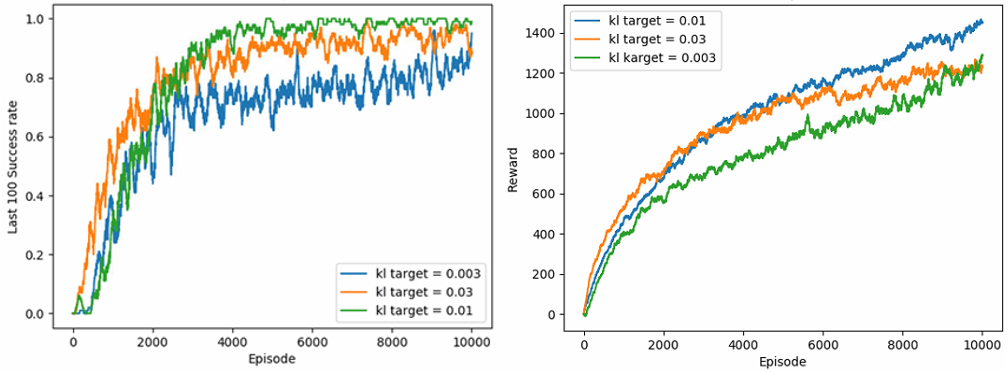
▶ Continual Multi-Agent Reinforcement Learning for Dynamic Environments
Objective
StarCraft II와 같은 동적 환경에서 다수의 에이전트가 변화하는 환경에 적응적으로 상호 협력적인 작업 정책을 효율적으로 학습할 수 있는 프레임워크를 개발
· 도전 과제-1: 개별 에이전트는 제한된 범위 안에서만 환경 인식 가능(Partial Observability)
· 도전 과제-2: 개별 에이전트가 아닌 팀 단위의 보상만 주어짐(Reward Assignment)
· 도전 과제-3: 아군 및 상대 팀의 구성이나 위치, 공격 상황이 역동적으로 변하는 환경에 대한 효과적 대응 요구(Unpredictable Dynamics)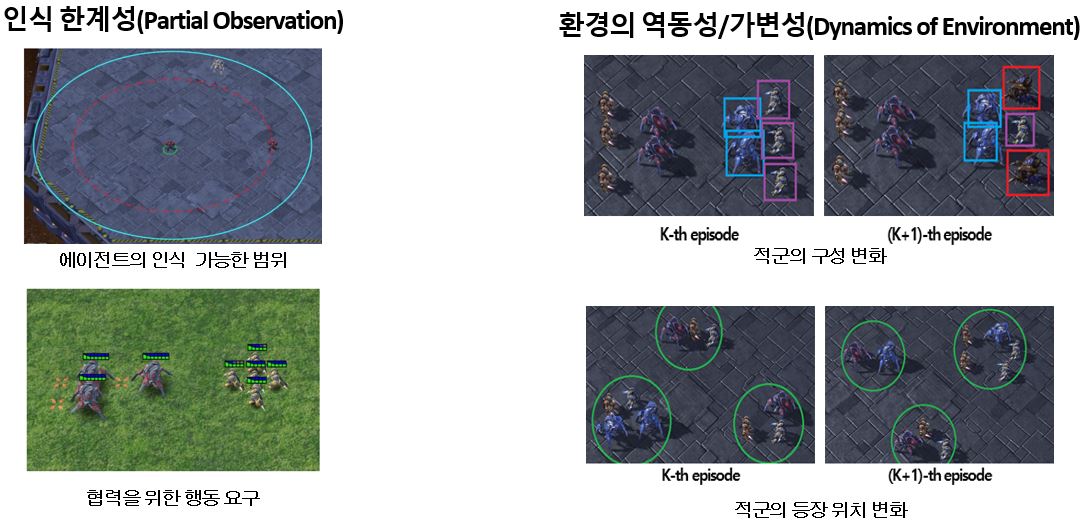
Approach
· 지속적인 Counterfactual Multi-Agent(COMA) policy gradients 적용
· 조정자 에이전트(Coordinator Agent)의 도움으로 개별 에이전트의 인식 한계성을 극복
· Counterfactual Baseline을 통한 팀 보상 기반의 개별 에이전트 기여도 부여
· 항시 조정자 에이전트의 존손으로 역동적으로 변하는 환경에 대해 효과적인 대응 가능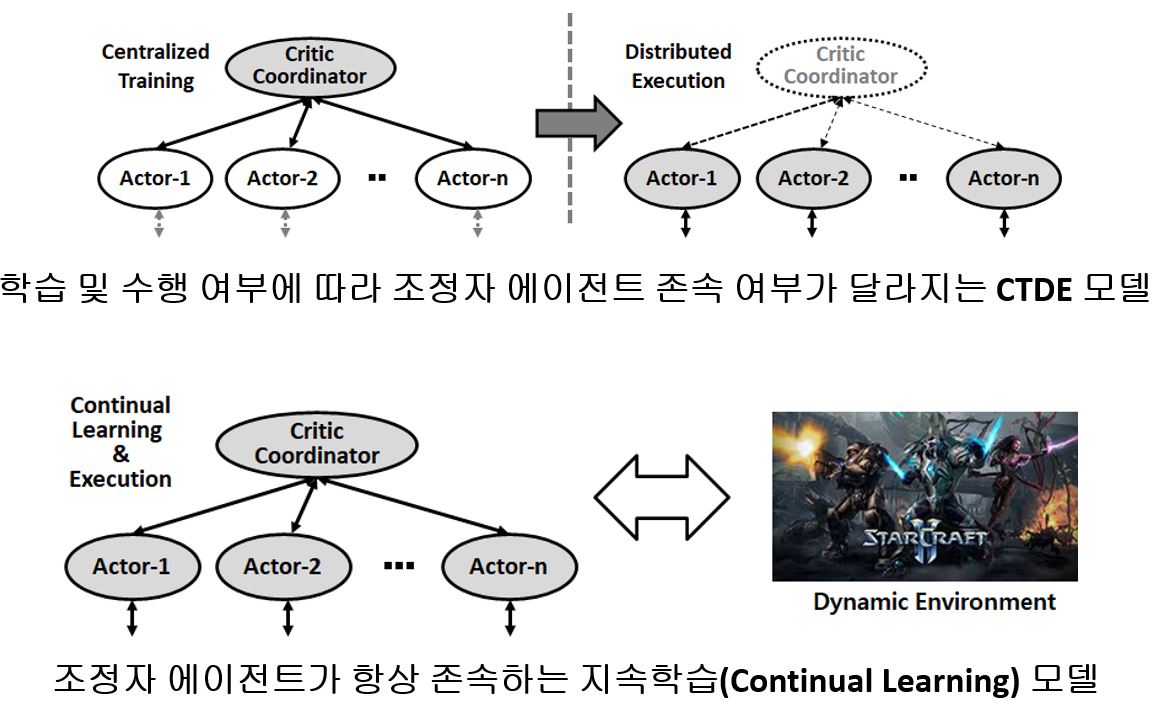
Application
