Research
Computer Vision
▶ An Efficient Mixture of LoRA Experts for Instruction-baed Multi-task Image Editing
Objective
· 자연어 지시(Instruction)에 따라 원본 영상의 구조를 유지하면서 원하는 편집을 수행하는 작업
· 대규모 영상 편집 확산 모델을 다양한 편집 작업으로 효율적으로 확장하기 위해 LoRA 및 MoE 기반의 파라미터 효율적인 학습 구조 필요
· 편집 작업별 전문가 영역을 어떻게 분할할 것인지에 대한 결정 필요
· 적은 수의 파라미터로 효과적인 전문가 모듈을 학습할 수 있는 방법 요구
· 입력 지시에 적합한 전문가를 선택하기 위한 라우팅 함수 학습 방식 결정 필요
· 다중 작업 영상 편집 결과를 효과적으로 평가할 수 있는 정량적·정성적 평가 방법 필요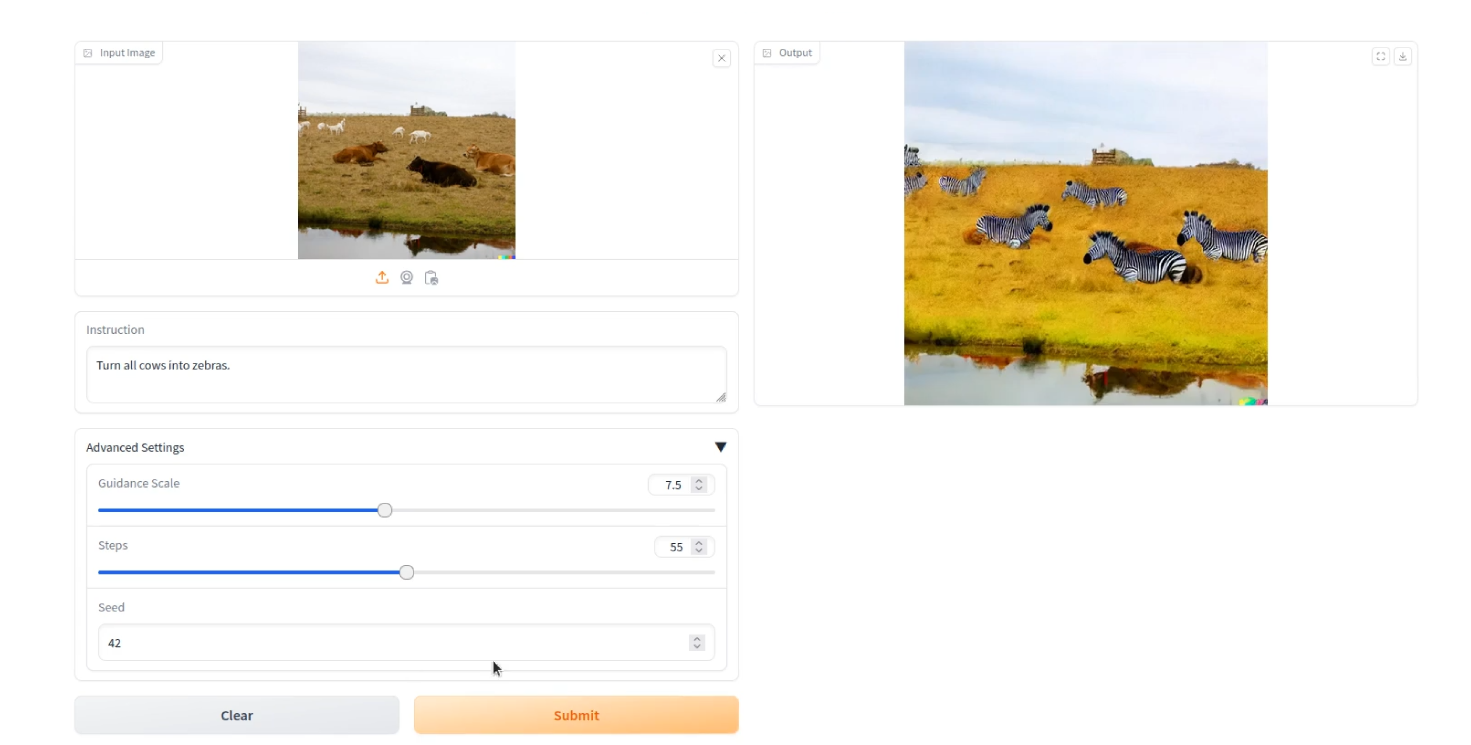
Approach
· 자연어 지시 기반 다중 작업 영상 편집을 위한 LoRA 전문가 혼합 모델 MOLIE(Mixture of LoRA experts for Instruction-based Multi-task Image Editing)를 제안
· Add, Remove, Replace, Change 등의 편집 연산(Operation) 중심으로 전문가 영역을 분할하여 다양한 편집 작업에 대응
· 사전 학습된 InstructPix2Pix 모델의 U-Net Up-blocks에 LoRA를 적용하여 파라미터 효율적인 전문가 모듈 학습 수행
· 입력 지시에 따라 적절한 전문가를 선택하고 복합 지시에 대해 여러 전문가를 조합할 수 있도록 MoE 기반 라우팅 구조 적용
· 편집 전후 영상의 구조 보존을 위해 자기 유사도(Self-Similarity) 기반 구조 손실 함수 적용
· 대규모 멀티모달 모델을 활용해 설계한 지시-영상 정렬(IIA) 평가 지표를 통해 편집 성능 평가 수행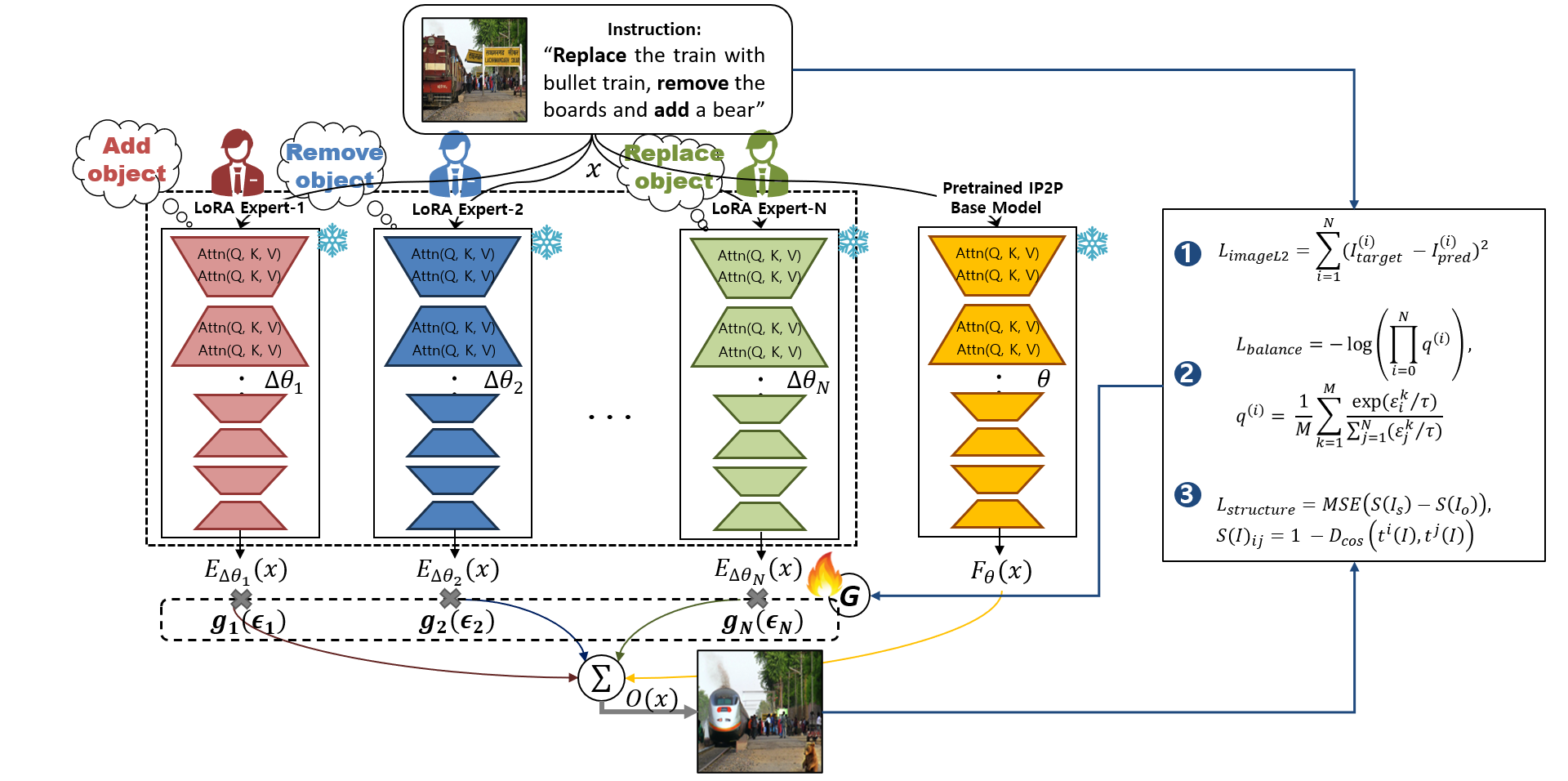
▶ CDTD-RVOS : A Referring Video Object Segmentation Model via Cross-modal Object Decoding and Referring Expression Decoupling
Objective
· RVOS(참조 비디오 객체 분할)는 비디오 안에서 자연어 문장에 해당하는 하나의 객체만을 정확하게 탐지, 분할, 추적하는 작업
· 자연어 문장에서 나타난 목표 단어가 무엇인지를 분석하여 찾는 능력을 요구
· 비디오 내의 목표 객체를 각 프레임마다 인식하며 추적하는 능력을 요구
· 자연어 문장의 목표 단어과 비디오 영상의 목표 객체 간 연관성을 찾기 위해 특징 융합 및 정렬하는 방식의 결정 필요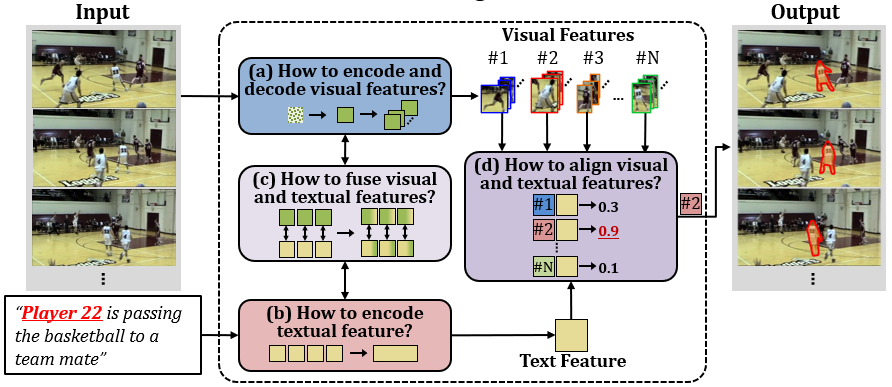
Approach
· 참조 비디오 객체 분할 작업을 위한 새로운 심층 신경망 모델을 제안
· 픽셀 • 프레임 • 비디오 수준의 시각적 특징을 모두 추출하여 목표 객체의 시-공간적 맥락정보를 효과적으로 검출
· 문장 내의 각 단어들을 구문적 역할에 따라 구분하여 문장에 등장하는 목표 물체 관련 정보를 인식
· 픽셀 • 프레임 • 비디오 수준에서 시각-언어 간 교차-모달 특징 융합을 진행하여 상호간의 정보를 반영
· 위치 정렬 손실과 의미 정렬 손실을 활용하여 비디오 내 객체와 문장 내 단어간의 연관성을 반영
▶ OV-3DRENet : 3D Region Mask Proposal and 2D-3D Visual Feature Ensemble for Open-Vocabulary 3D Semantic Segmentation
Objective
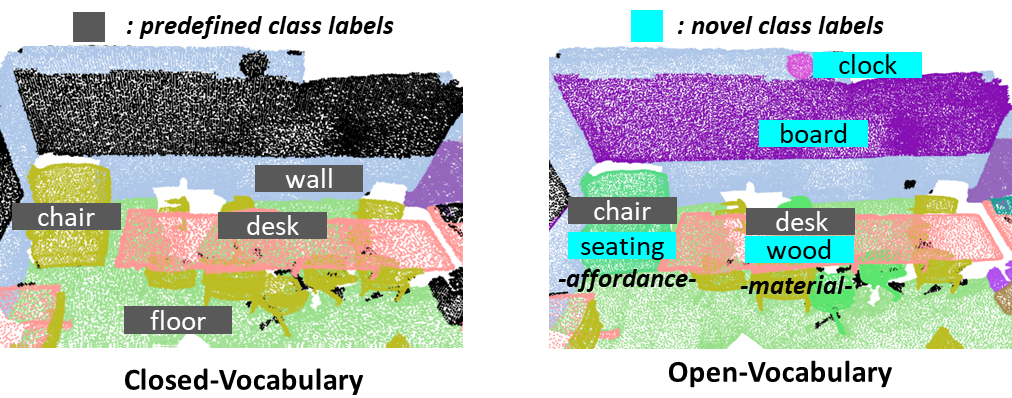
· 개방형 어휘 3차원 의미적 분할(Open-Vocabulary 3D Semantic Segmentation)은 포인트 클라우드를 의미적 단위로 분할하는 작업
· 새로운 분류 카테고리와 물체의 행동 및 재질 등 다양한 언어 어휘에 대한 인식 가능
· 파편화 문제를 해결하기 위해 포인트 수준의 분류 또는 영역 수준의 분류를 수행할 것인지 결정 필요
· 포인트 클라우드로부터 개방형 어휘 분류 레이블의 언어적 특징과 잘 정렬된 3차원 시각적 특징을 획득할 수 있는 능력 요구
· 멀티-뷰 RGB 영상들로부터 개방형 어휘 분류 레이블의 언어적 특징과 잘 정렬된 2차원 시각적 특징을 획득할 수 있는 능력 요구
· 추론 시 의미적으로 부합되는 개방형 어휘 분류 레이블들을 할당할 수 있는 2차원 및 3차원 시각적 특징들의 앙상블 방식의 결정 필요
Approach
· 다양한 어휘에 대해서도 분할이 가능한 새로운 개방형 어휘 3차원 의미적 분할 모델 OV-3DRENet(Open-Vocabulary 3D semantic segmentation Network with 3D Region mask proposal and 2D-3D visual feature Ensemble)을 제안
· 동적 앵커 박스-변형 개체 디코딩(Dynamic Anchor Box-Deformable Instance Decoding) 방식을 도입
· 사전 학습된 Mask3D를 3차원 영역 마스크 제안 모듈로 채용하여 영역 수준(region-level)의 분류 수행
· 분류 레이블의 제한 없이 다양한 어휘에 대한 추론을 위해, OpenScene을 사용하여 언어적 특징과 잘 정렬된 개방형 3차원 시각적 특징 획득
· 텍스트가 표현하는 의미적 단위로 정렬된 OpenSeg를 통해 언어적 특징과 잘 정렬된 개방형 2차원 시각적 특징 획득
· 2차원 및 3차원 영역 특징들과 텍스트 특징을 이용하여 영역 단위의 2차원-3차원 시각적 특징 앙상블(2D-3D visual feature ensemble) 기법 적용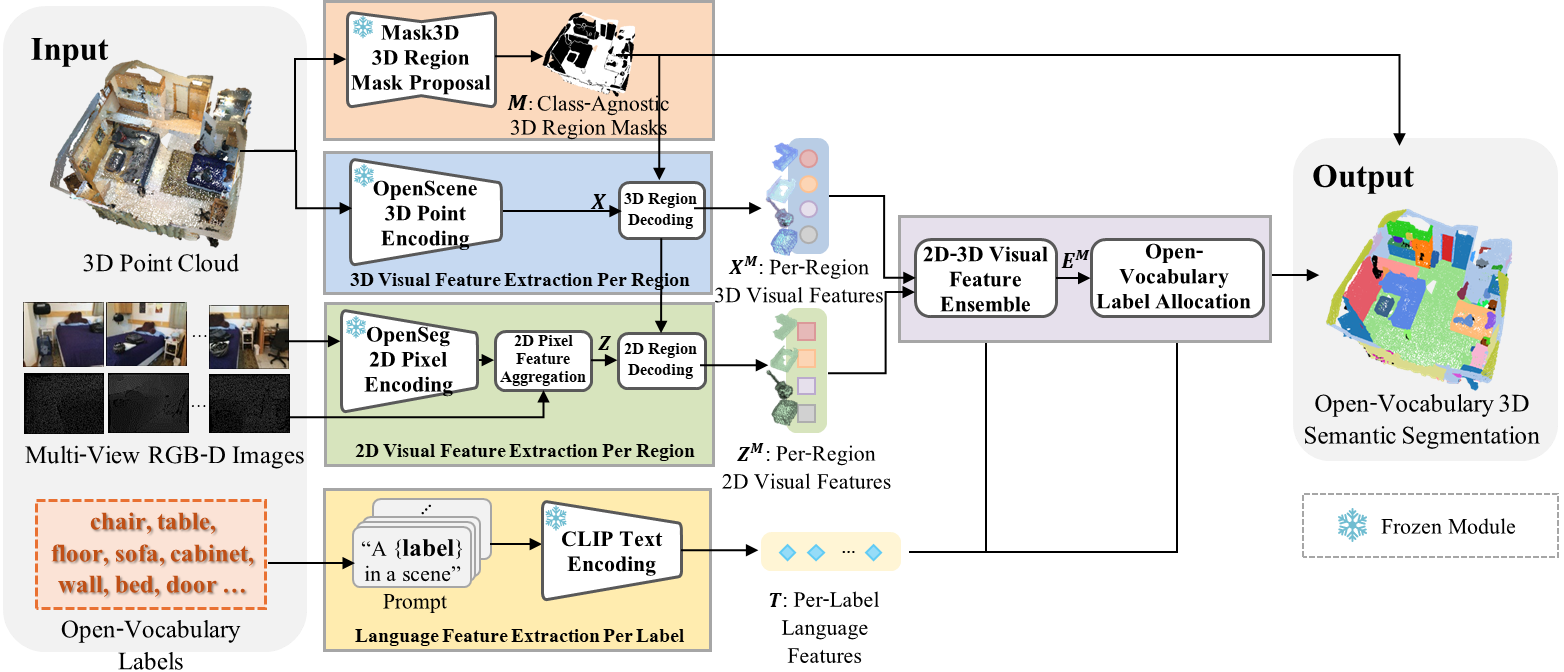
▶ Transformer-based Instance Decoding and Denoising Auxiliary Training for Efficient 3D Instance Segmentation
Objective
· 3D Instance Segmentation은 3차원 장면에 등장하는 개체들의 3차원 마스크와 클래스 레이블을 동시에 알아내는 작업
· 트랜스포머 기반 접근 방식은 다계층 디코더를 통해 전체 포인트 특징들 중, 개체 별 특징들을 쿼리에 디코딩하고, 디코딩된 특징을 토대로 마스크와 클래스 레이블을 예측
· 쿼리 디코딩 품질 향상을 위해 디코더 계층 단위로 정제할 정보 결정이 필요함
· 디코딩 과정에서 특징 집계 정확도 향상을 위해 쿼리에 포함시킬 개체별 위치 정보 결정이 필요함
· 디코딩 수렴성을 향상시키기 위해 디코더에 입력되는 쿼리의 초기값 설정 방식 결정이 필요함
· 주작업 수행 능력과 수렴성을 향상시키기 위해 학습 시간 동안 추가로 적용할 보조 작업 학습 결정이 필요함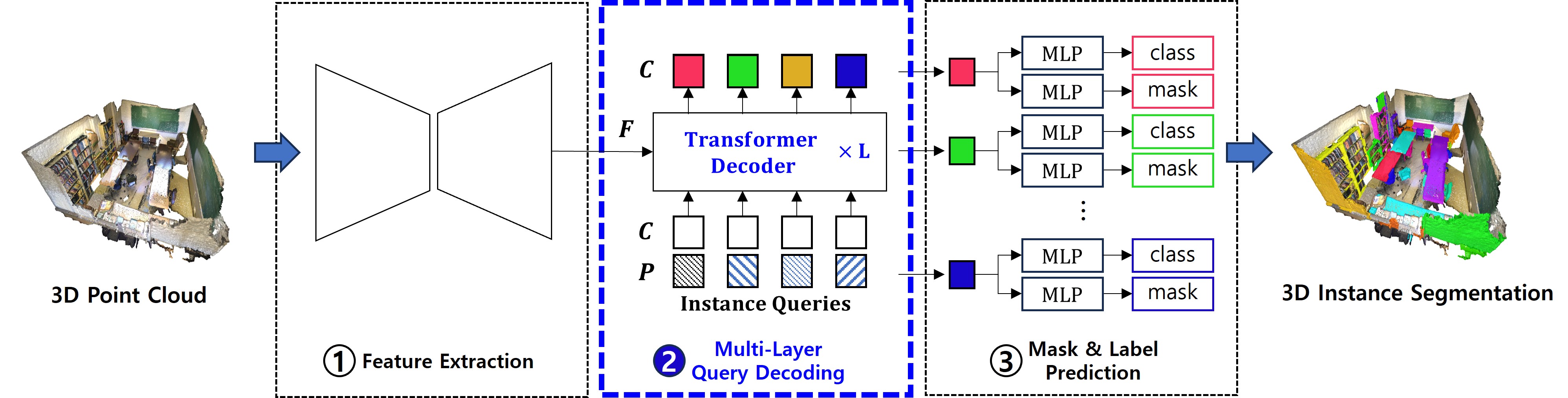
Approach
· 트랜스포머 기반 모델 설계 이슈들과 기존 연구들의 문제점들을 고려하여, 개선시킨 새로운 트랜스포머 기반의 3차원 포인트 클라우드 개체 분할 모델을 제안함
· 쿼리 디코딩 과정의 정확도 향상을 위해 트랜스포머 디코더 계층 단위의 마스크(Mask), 위치 정보(Position), 콘텐트(Content) 정제 적용
· 쿼리별 정제 특징 품질 향상을 위해, 개체 쿼리의 위치 정보 인코딩(Poisitional Encoding)에 3차원 경계 상자 정보(3D Bounding Box)를 활용
· 상위 K개의 분류 신뢰도(Top K Class Confidence)를 토대로, 개체와의 연관성이 높다고 판단되는 특징들을 쿼리의 초기화에 사용
· 모델 학습동안 노이즈 제거 보조 학습(Denoising Auxiliary Training)을 적용하여, 학습 수렴 가속화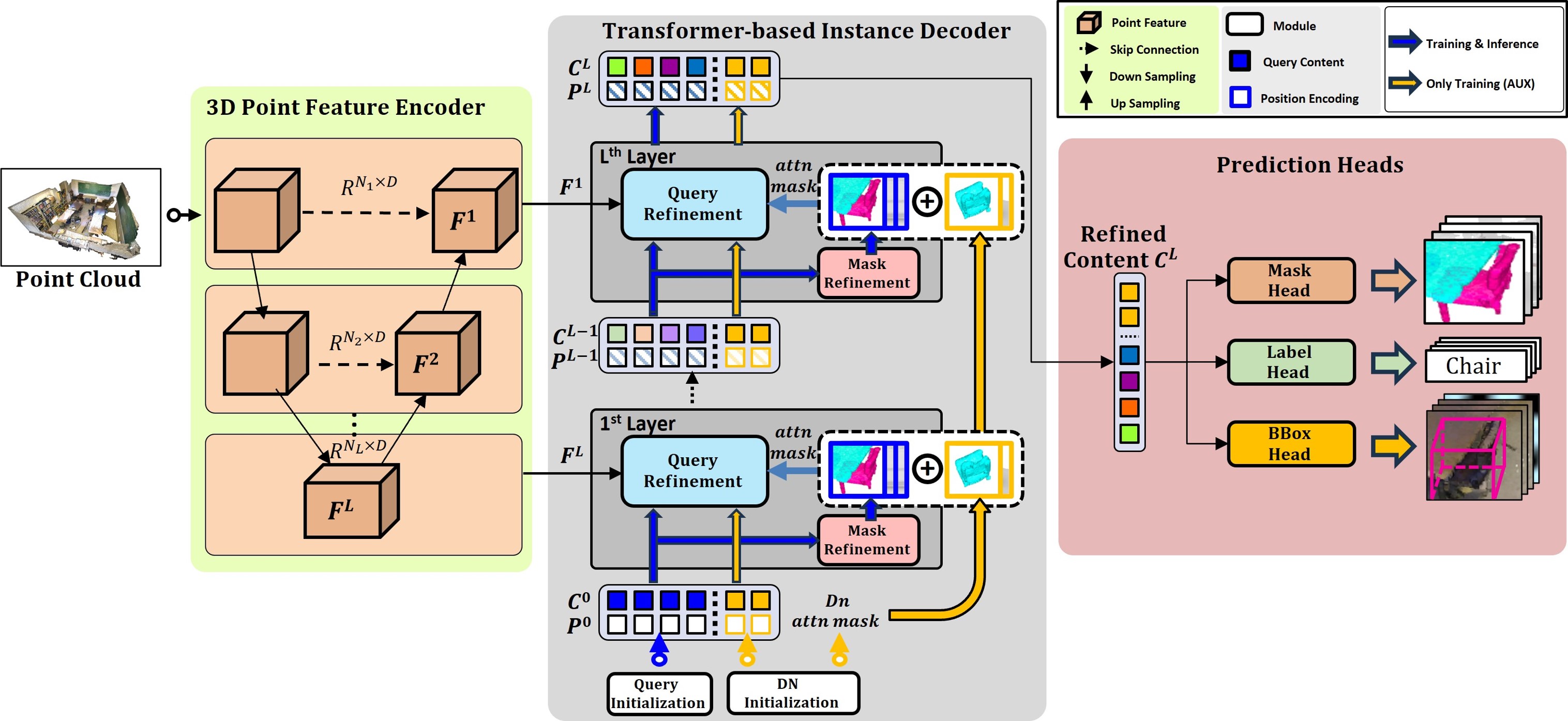
▶ Dynamic Anchor Box-Deformable Instance Decoding and Inter-Frame Instance Association for Online Video Instance Segmentation
Objective
· 비디오 개체 분할(Video Instance Segmentation, VIS)은 입력 비디오에 등장하는 다수의 개체에 대해 탐지(detection), 분류(classification), 분할(segmentation), 추적(tracking)을 동시에 수행해야 하는 작업
· 오프라인(offline)과 온라인(online) 2가지 비디오 개체 분할 방식으로 나뉘며, 더욱 강력한 과거 프레임과의 개체 연결과 추적 알고리즘이 필요한 온라인 방식에 집중하여 연구를 진행
· 입력 비디오 프레임 각각(intra-frame)에 등장하는 개체들을 올바르게 분할(instance segmentation)하기 위한 공간적 맥락 파악 능력이 요구됨
· 프레임들 간(inter-frame) 개체들을 서로 정확하게 연결(instance association)하기 위한 시간적 맥락 파악 능력이 요구됨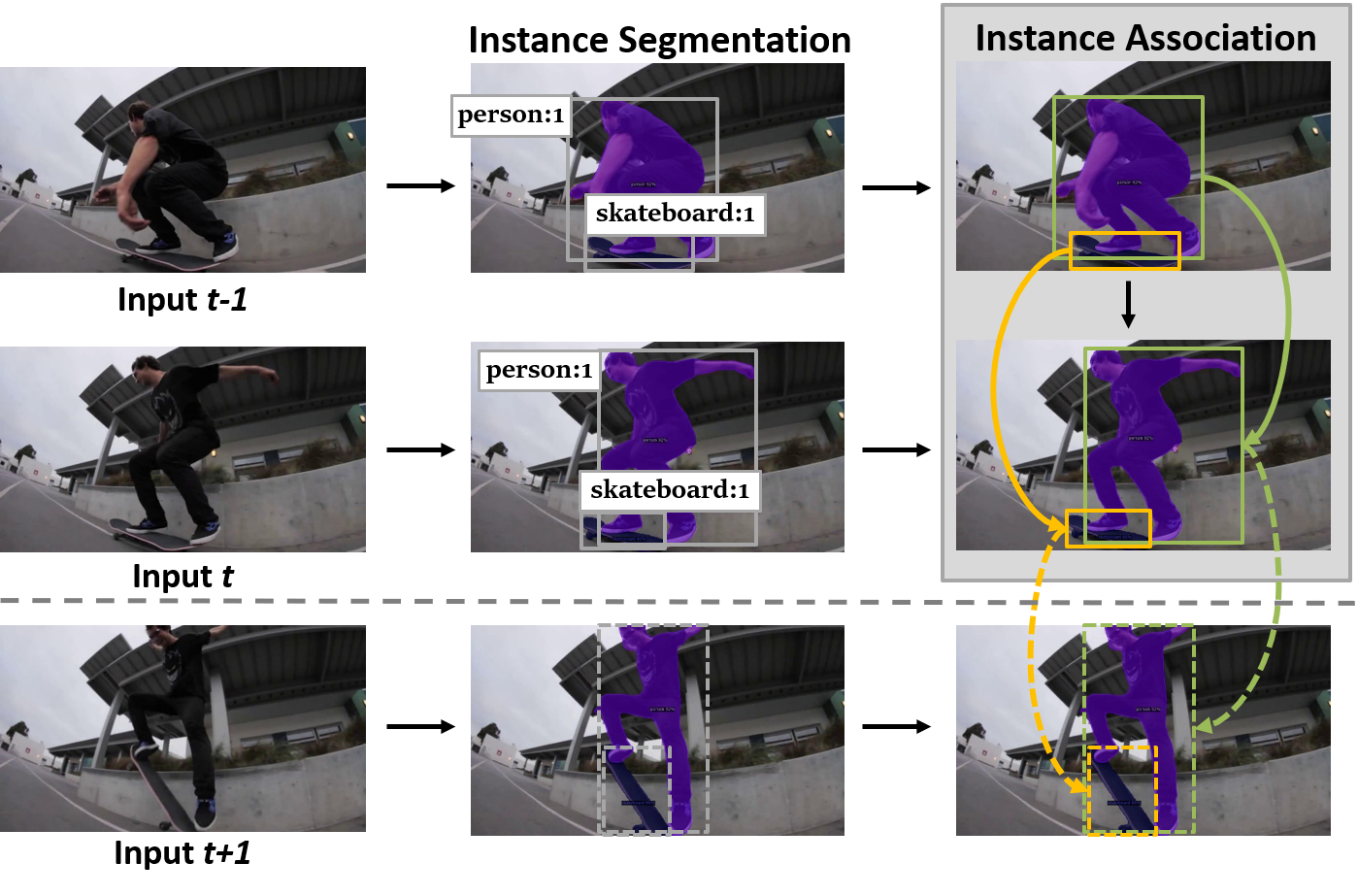
Approach
· 온라인 비디오 개체 분할 문제를 위한 트랜스포머 구조 기반의 심층 신경망 모델인 DAB-D-VIS(Dynamic Anchor Box-Deformable-VIS)를 제안
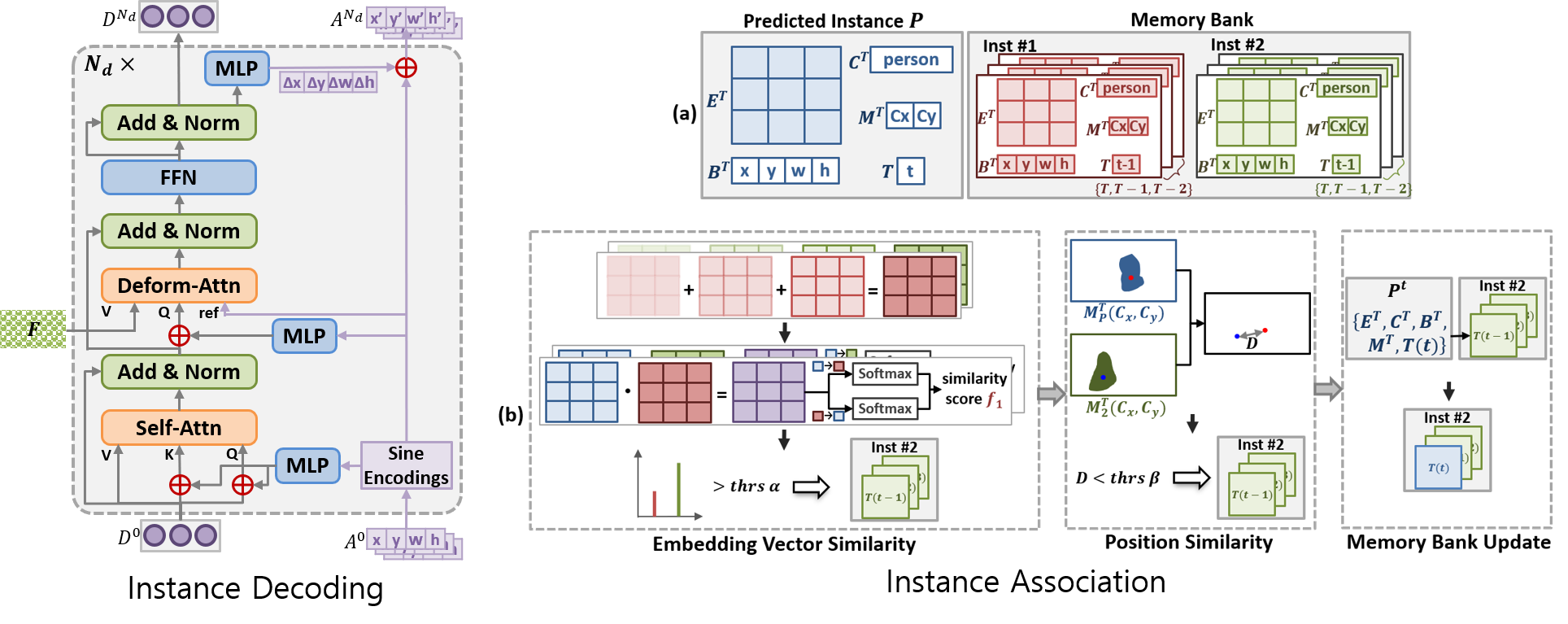
· 동적 앵커 박스-변형 개체 디코딩(Dynamic Anchor Box-Deformable Instance Decoding) 방식을 도입
· 동적 앵커 박스(dynamic anchor box)를 통해 개체의 위치(x,y)와 영역(w,h)을 모두 표현하는 경계상자(bounding box)들을 디코더(decoder)를 통해 정제
· 변형 크로스 어텐션(deformable cross attention)을 통해 참조 포인트(reference point) 주변의 키 포인트(key point)들 대상으로 크로스 어텐션 범위를 제한
· 메모리 뱅크에 과거 개체 정보들을 저장하여 현재 탐지 개체와 메모리 뱅크 속 과거 개체를 서로 연결
· 먼저 대조 임베딩 벡터(contrastive embedding vector) 간 양방향(bi-directional) 유사도를 계산한 다음, 개체 위치 간의 유클리드 거리를 계산하는 두 단계로 구성된 새로운 위치 인지 개체 연결(position-aware instance association) 방식을 제시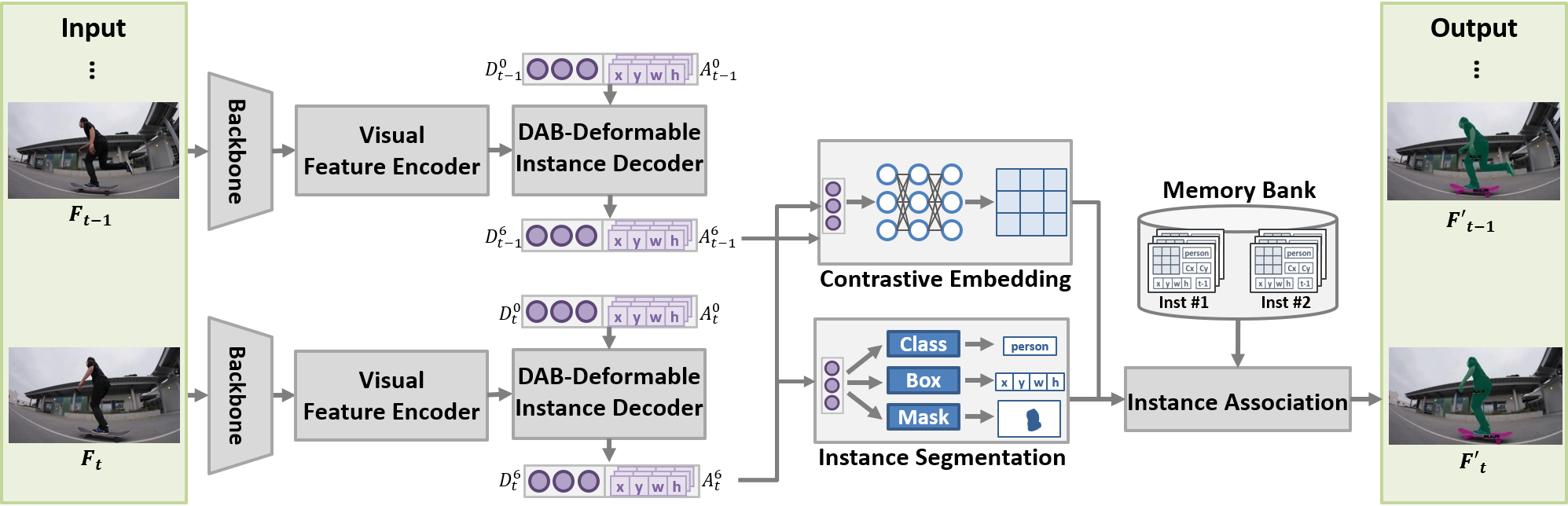
▶ GNN-based Spatial Context Reasoning and Large Language Model(LLM) Prompting for Effective 3D Point Cloud Scene Graph Generation
Objective
· 3차원 장면 그래프 생성(3D Scene Graph Generation, 3DSGG)은 입력 포인트 클라우드에 포함된 장면 구성 요소들 간의 3차원 공간 관계를 나타내는 하나의 지식 그래프를 생성하는 작업
· 장면 그래프의 각 노드(node)는 장면 속의 물체를, 각 간선(edge)은 물체들 간의 관계를 나타냄
· 3차원 포인트 클라우드의 많은 점들에 대한 기하학적 특징 추출 능력이 요구됨
· 이웃한 물체들 간의 공간적 맥락 정보를 어떠한 방식으로 전달하고 반영할 지 결정하는 능력이 요구됨
· 범주별 데이터 불균형 문제를 해결하기 위해 각 물체의 특성이나 물체들 간의 공간적 관계에 관한 사전 지식 확보 및 활용 방법이 필요함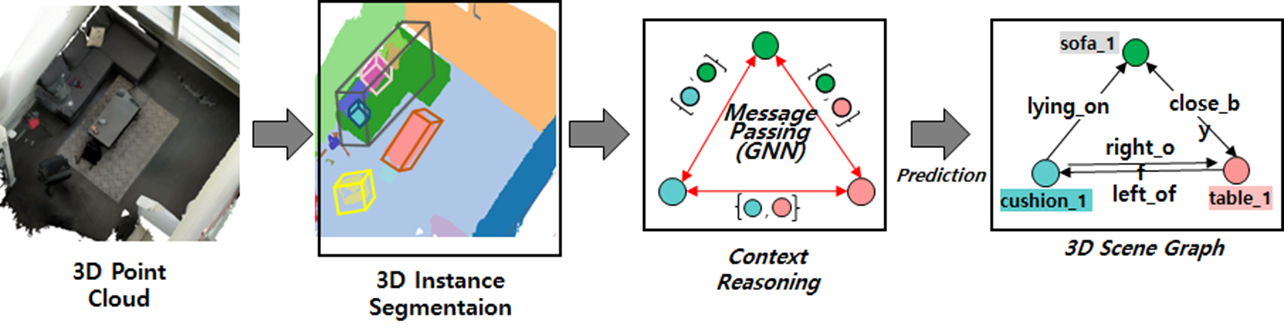
Approach
· 장면 그래프 생성 문제를 위한 대규모 언어 모델 기반의 심층 신경망 모델인 L3DSG(LLM-based 3D Scene Graph Generation)를 제안
· Transformer 신경망 구조의 자기-주의 집중(self-attention) 계층을 적용하여 기하학적 특징 추출 방법 제안
· 그래프 주의 집중 신경망 NE-GAT를 이용하여 이웃 물체 노드들과의 맥락 정보를 차등적으로 반영
· 대규모 언어 모델(GPT-3)로부터 사전 지식을 확보하여 최종 장면 그래프 생성에 활용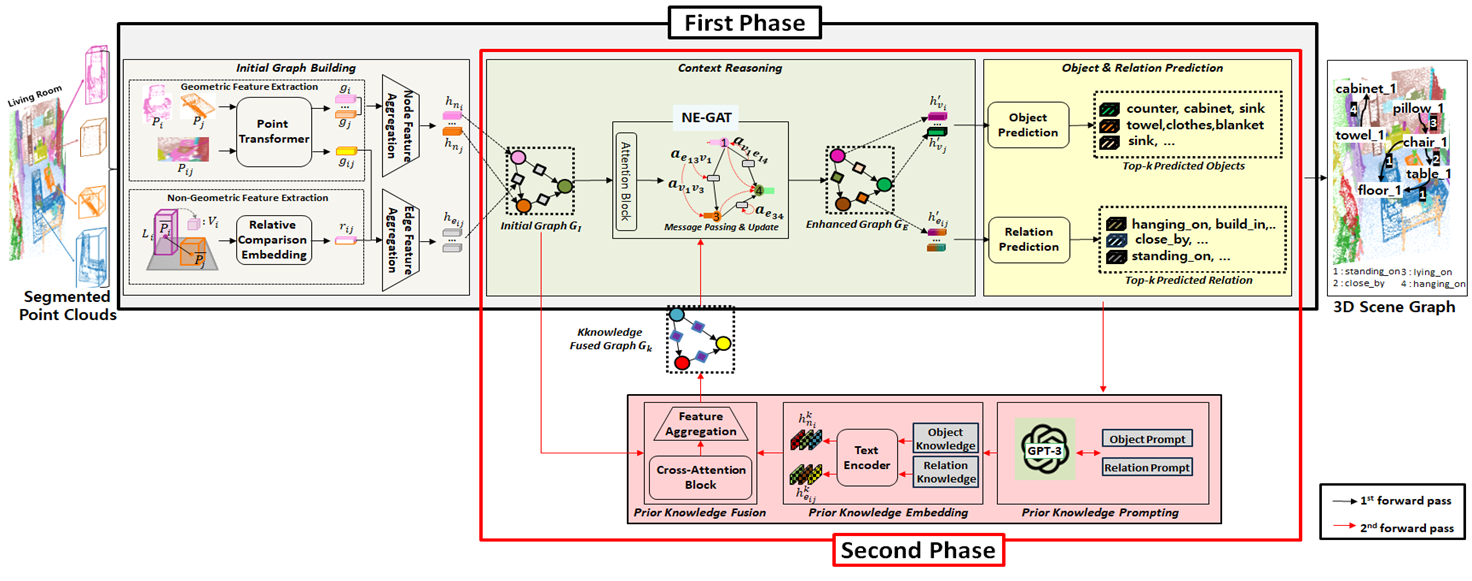
▶ Unseen Object Pose Estimation using a Monocular Depth Estimator
Objective
· 6D Pose Estimation은 3차원 공간에서 카메라를 중심으로 물체의 3축 회전과 3축 변환을 알아내는 작업
· 개체 수준(instance-level)과 범주 수준(category-level) 2가지 6D Pose Estimation 방식으로 나뉨
· 개체 수준 방식의 경우, 인식하고자 하는 각 물체 개체별로 정확한 CAD 모델을 필요로 하므로 이미 알고있는 물체(known/seen object)들에 대해서만 적용 가능
· 범주 수준의 방식의 경우, 인식 대상 물체의 개체별 CAD 모델을 요구하지 않기 때문에 미지 물체(unknown/unseen object)들에도 적용 가능. 대신 해당 물체가 속한 범주의 표준 3차원 모델 학습이 필요함
Approach
· 깊이 영상 대신 단안 카메라 깊이 추정(monocular depth estimation) 기술을 적용함으로써, RGB 영상만을 이용하는 새로운 미지 물체 자세 추정 모델을 제안함
· 전역적 정보 처리를 위해 트랜스포머(Transformer) 기반 신경망 블록이 추가된 깊이 추정기를 이용
· 깊이 범위(depth range)를 다수의 구간들(bins)로 나누고, 각 구간의 중심 값을 입력 영상에 맞게 적응적으로 추정함
· 범주형 3차원 표현(NOCS) 예측 헤드가 추가된 Mask-RCNN 기반의 범주형 물체 자세 추정 네트워크를 채용
· 깊이 추정기가 예측한 깊이 지도(depth map)로 재구성한 3차원 표현(reconstrcuted represenation)과 범주형 3차원 표현(category representation)의 정렬(align) 작업을 통해, 인식 대상 물체의 자세를 추정함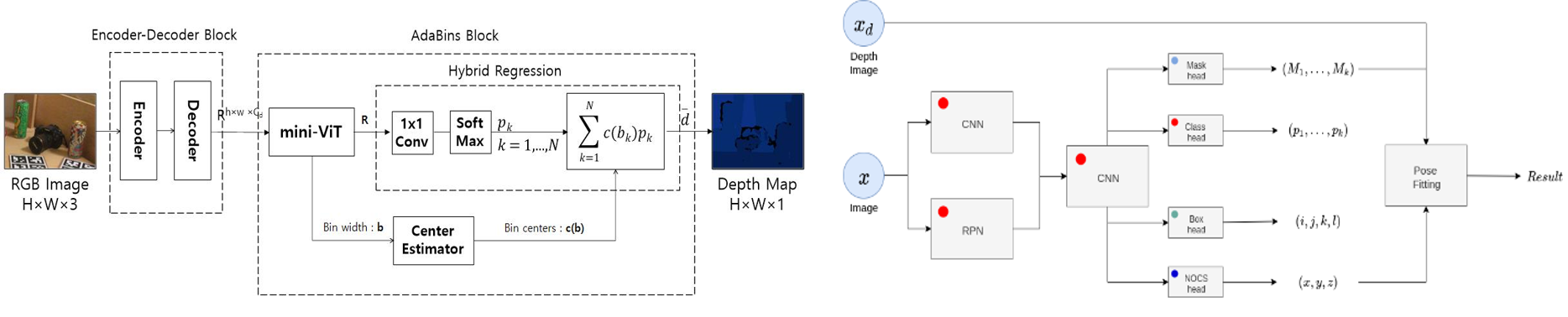
▶ Context-Dependent Video Data Augmentation for Human Instance Segmentation
Objective
· 비디오 인물 개체 분할은 비디오에 등장하는 복수의 주요 인물들에 대한 탐지(detection), 분류(classification), 분할(segmentation), 트래킹(tracking)을 동시에 수행하는 작업
· 드라마 비디오 인물 개체 분할을 위해 드라마 '미생'을 대상으로 학습 및 검증 데이터 집합 MHIS(Miseang Human Instance Segmentation Dataset) 생성
· 신규 데이터 집합 MHIS의 등장인물들 간의 데이터 불균형 문제(class imbalance problem)를 해결함으로써, 비디오 인물 개체 분할 성능 향상을 목표로 함
Approach
· 목표 및 배경 비디오 클립의 시공간적 맥락을 고려한 새로운 비디오 데이터 보강 기법 CDVA(Context-Dependent Video Data Augmentation) 제안
· CDVA는 목표 및 배경 클립 짝짓기, 맥락-의존적 영역 선정, 보강 클립 생성 등 3단계로 수행
· MHIS는 Youtube-VIS와 유사한 레이블 스키마로 설계
· 인물 클래스는 드라마 주연들로 이루어진 6개 클래스와 이외의 인물들을 나타내는 someone 클래스로 총 7개 클래스로 구성
· 비디오 인물 개체 분할을 위한 심층 신경망 기본 모델로 Transformer 기반의 비디오 개체 분할 모델인 SeqFormer 활용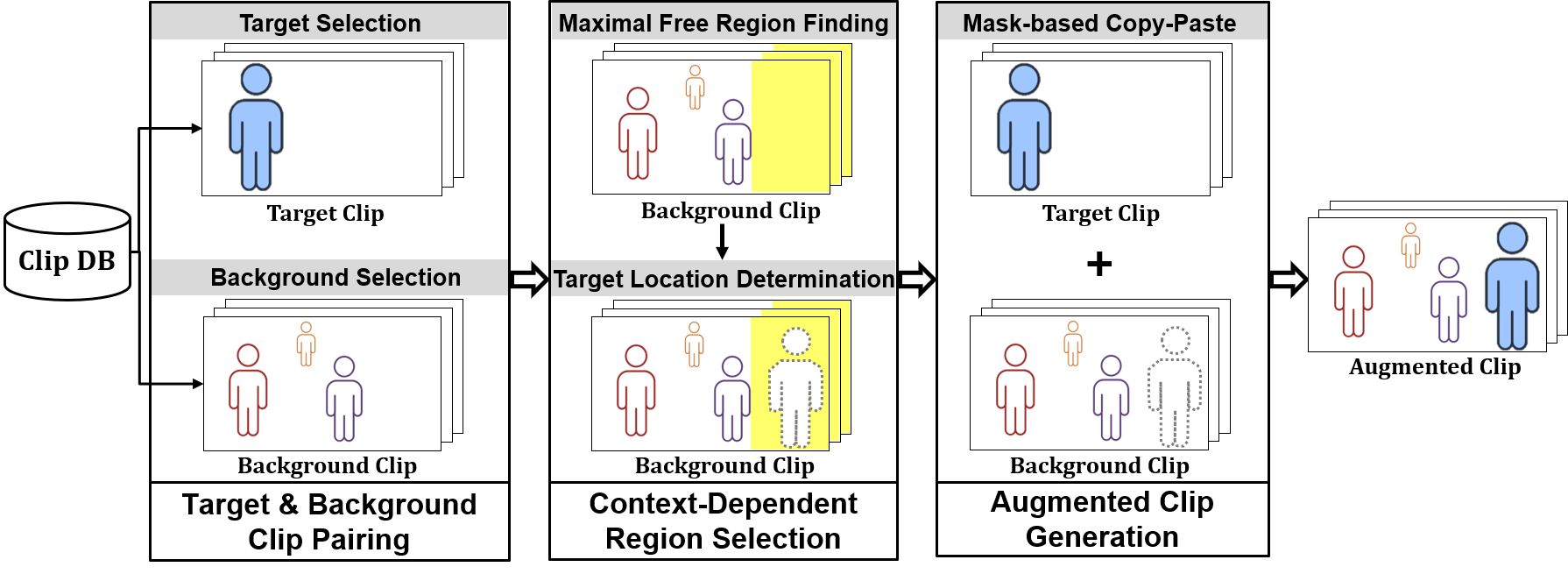
▶ Spatio-Temporal Context Embedding for Video Relation Detection
Objective
· 비디오 관계 탐지(VidVRD)는 비디오에 등장하는 물체들 간의 동적 관계와 시간적 구간을 탐지해내는 비디오 장면 이해 작업 중 하나
· 비디오에 등장하는 물체들 간에는 동시에 다양한 관계들이 존재할 수 있으며, 이러한 관계들도 시간에 따라 동적으로 변화할 수 있음
· 효과적인 비디오 관계 탐지를 위한 심층 신경망 모델 설계를 위해서는 관계 탐지 구간 설정 문제와 시공간 맥락 추론 문제를 필수적으로 해결해야 함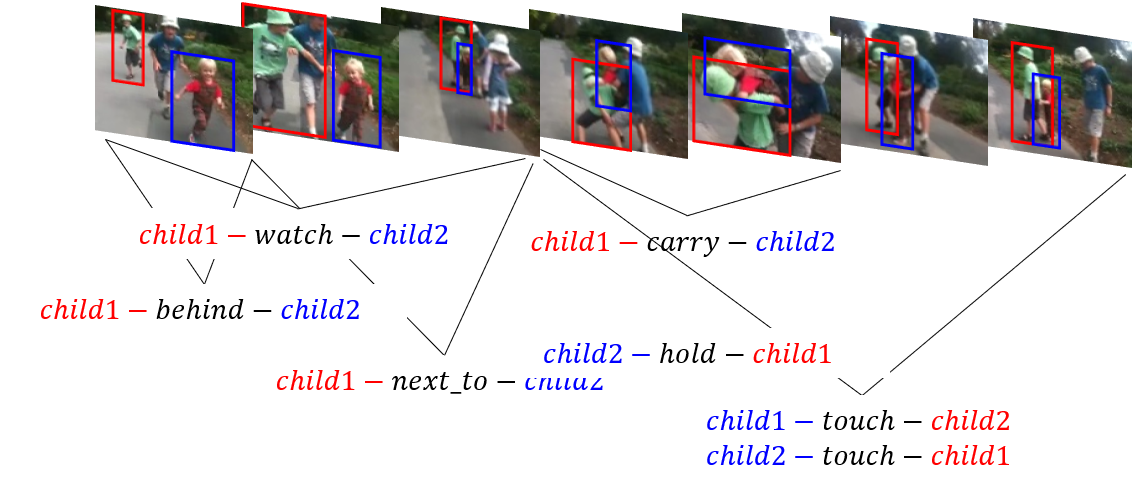
Approach
· 비디오 관계 탐지 모델인 Spatio-Temporal Context-aware Graph Network(ST-CGN) 제안
· ST-CGN은 인스턴스 기반 접근법과 새로운 시공간 맥락 추론 ST-HSA을 결합한 모델
· 인스턴스 기반 접근법은 비디오 전체 구간의 개별 물체 인스턴스(instance) 탐지 및 ID 부여
· 시공간 맥락 추론 ST-HSA는 인스턴스 쌍을 대상으로 시공간 맥락 추론
· 시공간 맥락 추론 ST-HSA는 그래프 신경망 HGN와 Transformer Self-Attention 신경망 모듈을 이용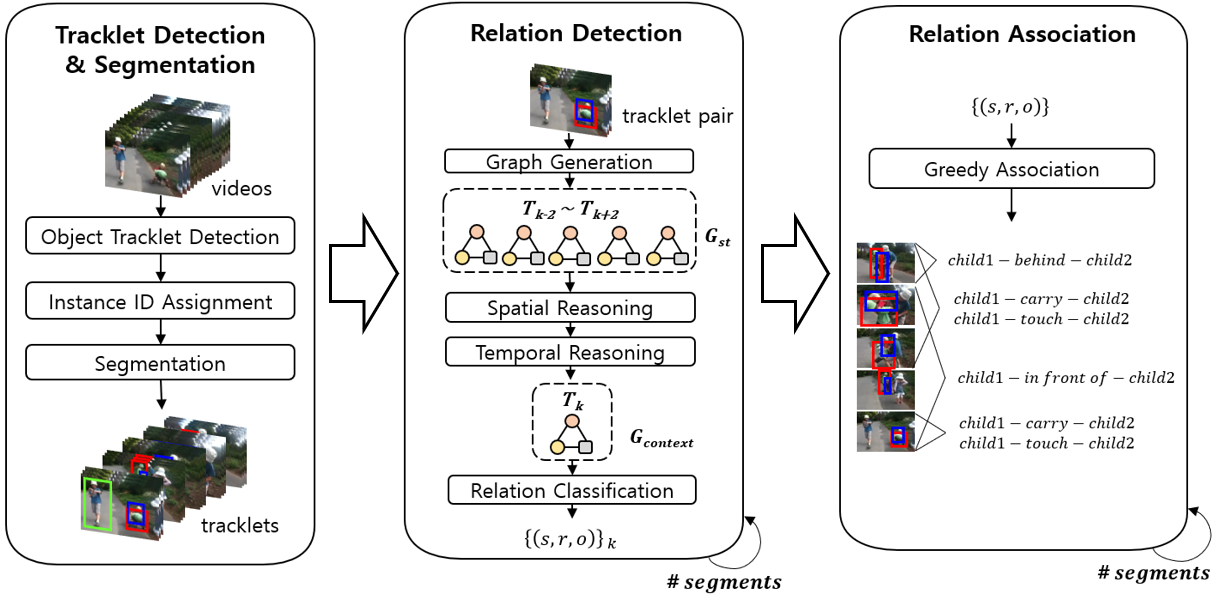
▶ Video Scene Graph Generation with Spatio-Temporal Graph Neural Network
Objective
· 비디오 장면 그래프 생성(Video Scene Graph Generation, VidSGG)은 하나의 비디오가 주어졌을 때, 비디오속 등장하는 물체와 그들 간의 관계를 추론하여
그래프로 표현하는 연구
· 과도하게 생성되는 물체 트랙 쌍(tracklet pairs)들 중에서 관계가 있을 쌍들 만을 가려낼 수 있는 물체 쌍 제안 방법(tracklet pair proposal)이 요구됨
· 물체(object)와 관계(relationship)의 특징 정보에 시 공간 맥락 정보(Spatio temporal context)를 효과적으로 반영할 수 있는 방법이 요구됨
· 시간적 필터링(temporal filtering), 사전학습된 신경망과 통계적 정보를 이용하는 관계성 평가 방법(neural net scoring and statistical scoring)을 사용하는
새로운 물체 쌍 제안 방법을 제시
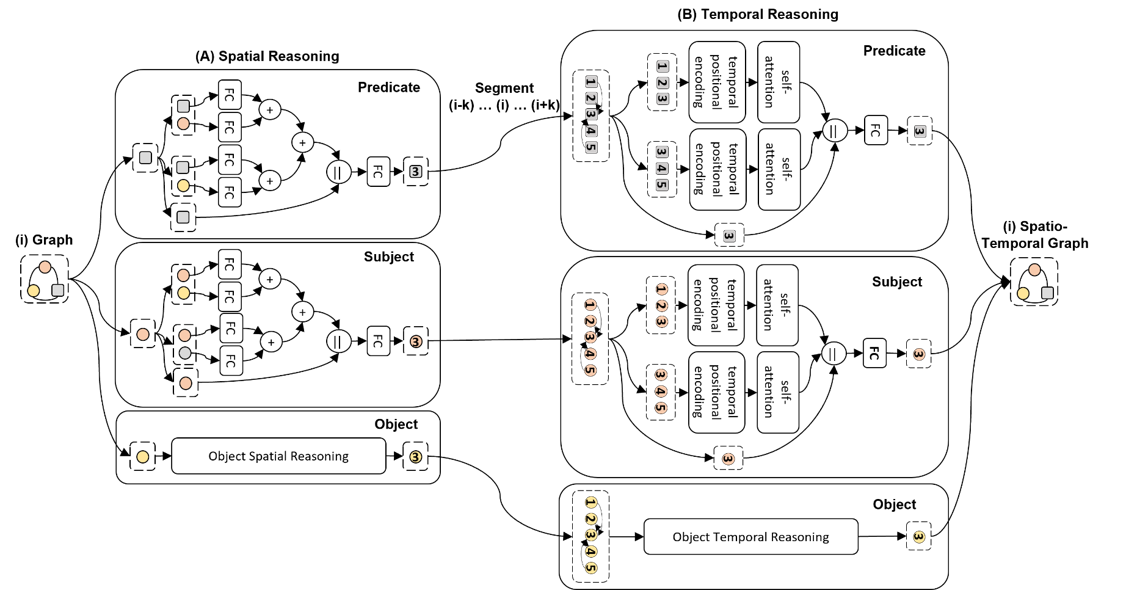
· 시-공간 정보를 반영한 시-공간 맥락 그래프(spatio temporal context graph)와 그래프 신경망 기반의 맥락 추론 방법(context reasoning) 제시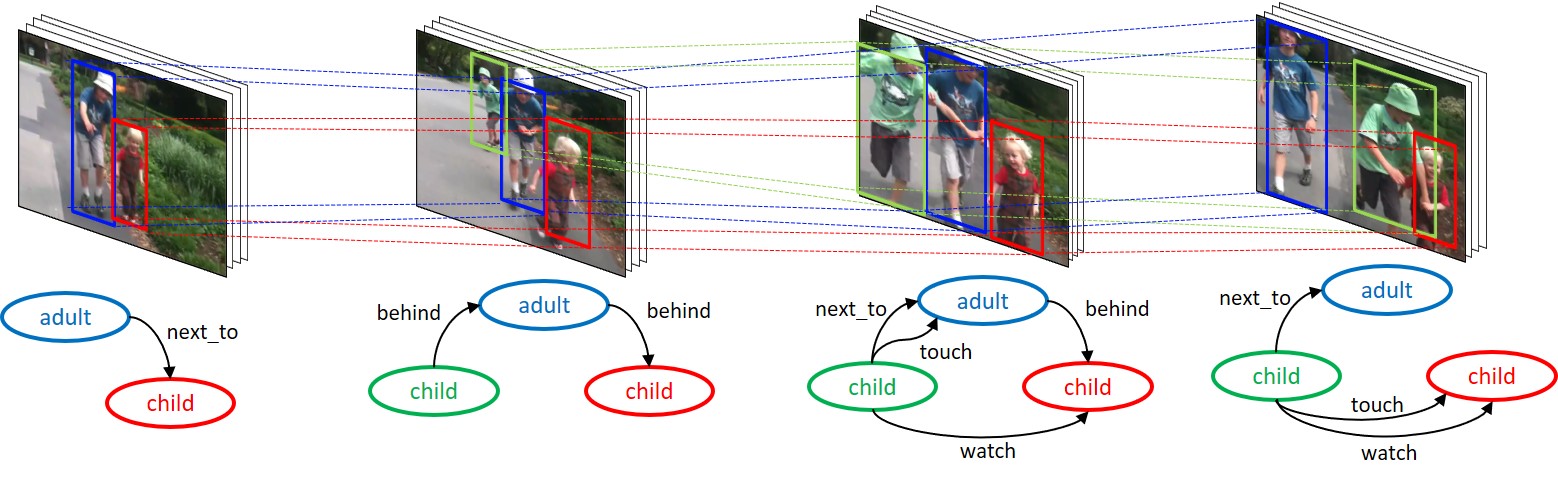
Approach
· 물체 트랙 쌍 제안 단계에서는 시간적 필터링, 물체의 클래스 분포도를 이용하는 사전 학습된 신경망과 데이터 집합의 통계적 정보를 이용한 통계적
평가 방법을 이용하여 희소 그래프(sparse graph) 생성
· 맥락 추론 단계에서는 첫번째로, 시공간 맥락 추론을 위한 두 물체 사이의 거리에 기반한 공간 주의 집중(spatial attention)과 시간적 겹침 정도(temporal attention)에
기반한 시간 주의 집중 적용
· 두번째로 그래프 신경망을 이용한 물체와 관계들 사이의 시각 맥락 추론(visual context reasoning)과 의미적 맥락 추론(semantice context reasoning)을
적용하여 맥락 그래프(context graph) 생성
· 분류 단계에서는 관계의 데이터 불균형(relationship class imbalance problem) 문제 해결을 위한 클래스 가중치(class weighting) 적용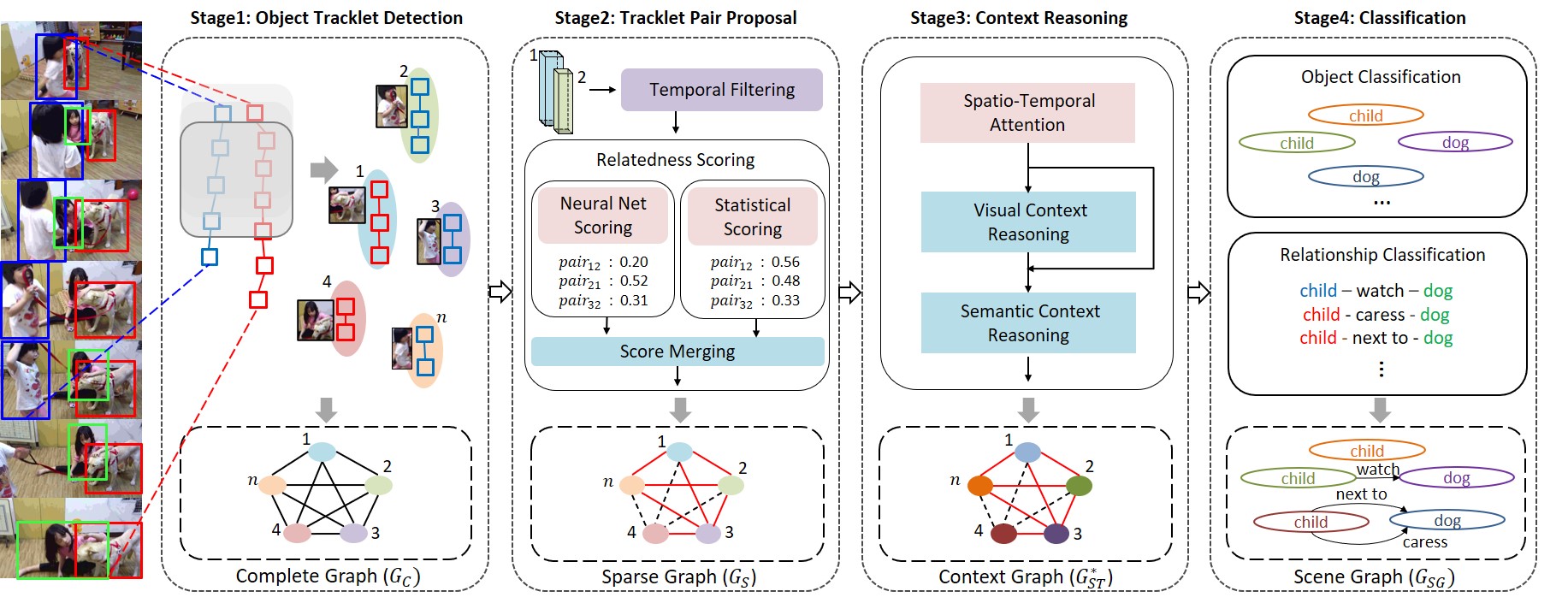
▶ Hybrid Learning for Vision-and-Language Navigation Agents
Objective
· 시각-언어 이동(VLN)은 가상환경 내에서 자율 에이전트가 자연어 지시와 실시간 입력 영상을 토대로 목적지까지 이동해야 하는 지능 작업
· Matterport3D 시뮬레이터와 R2R(Room-to-Room) 벤치마크 데이터 집합을 모델 학습과 성능 검증에 이용
· VLN 작업에 적합한 효율적인 심층 신경망 모델(deep neural network model) 설계
· 새로운 환경에서의 탐색 작업 성능을 위한 일반화(generalization) 요구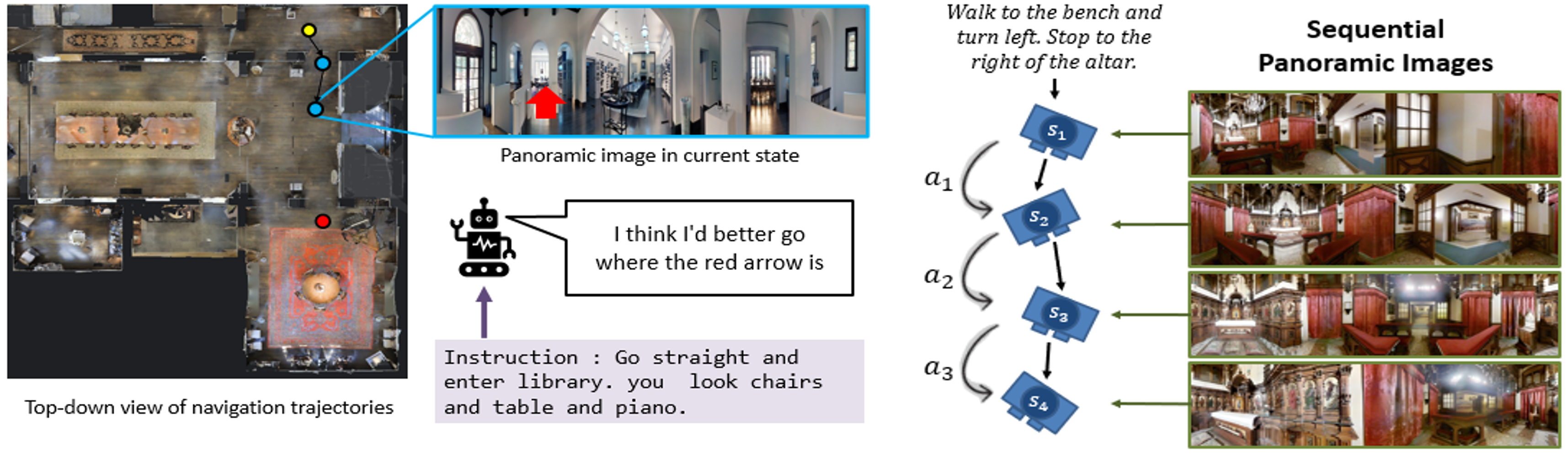
Approach
· 시각과 언어 기반의 이동(VLN) 문제를 위한 새로운 학습 모델 제시
· 모방 학습과 강화 학습을 결합한 복합 학습 (Hybrid Learning Combining Imitation learning and Reinforcement learning, CIR)을 채택
· 정답 경로 기반 보상 함수 (Region Based Alignment, RBA) 제안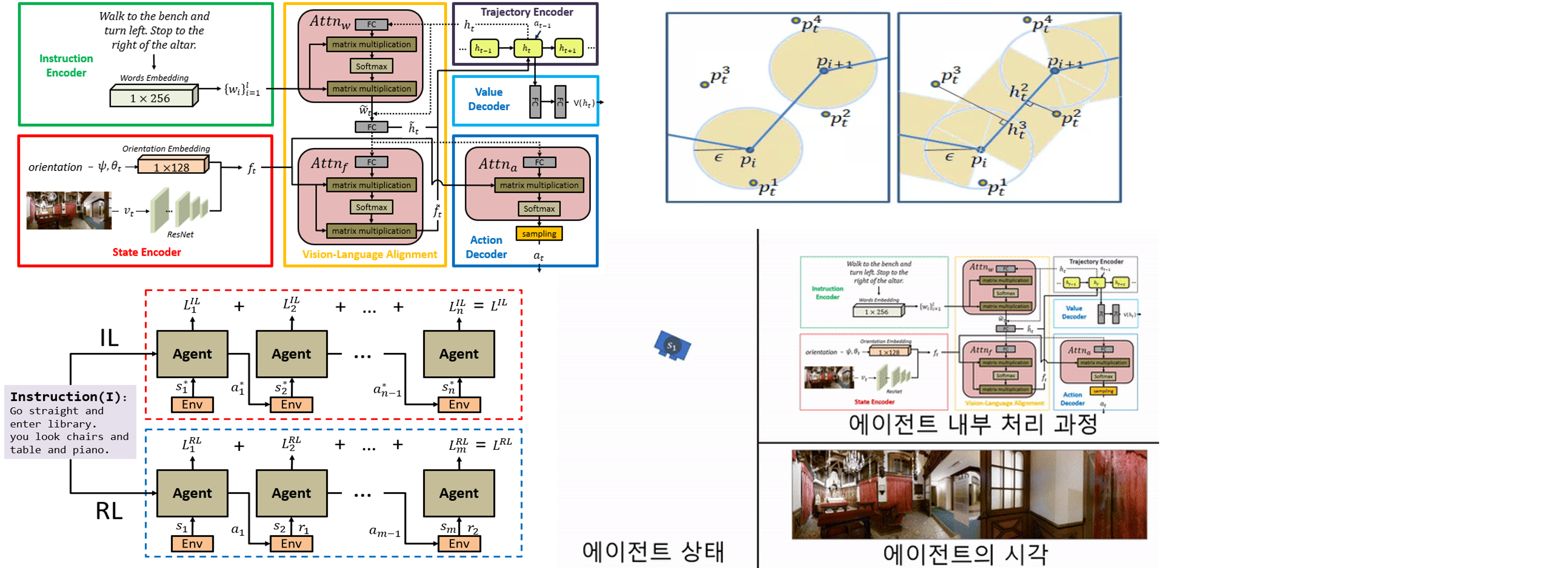
▶ Visual Commonsense Reasoning with Pretrained Multimodal Co-Embedder
Objective
· 영상 기반 상식 추론(Visual Commonsense Reasoning)은 하나의 영상, 질문, 응답 리스트가 주어졌을 때, 가장 적절한 답변과 근거를 제시하는 연구
· 서로 다른 타입의 데이터를 어떻게 정렬할 것인가에 대한 멀티 모달 상호 정렬(alignment) 문제를 해결해야함
· 문제 해결에 필요한 기초 개념 지식을 어떻게 확보하고, 임베딩(embedding)하며, 기존 정보와 통합하여 학습할지에 관한 상식 습득 문제를 해결해야함
· 영상, 자연어 정보 뿐만 아니라, 지식 정보까지 사용하는 새로운 사전 학습된 멀티 헤드 어텐션 모델(Pretrained multi-head attention model)을 제안
· 별도의 외부 지식(external knowledge)을 추출 및 사용하기 위한 지식 추출 모듈(knowledge extraction module)을 제안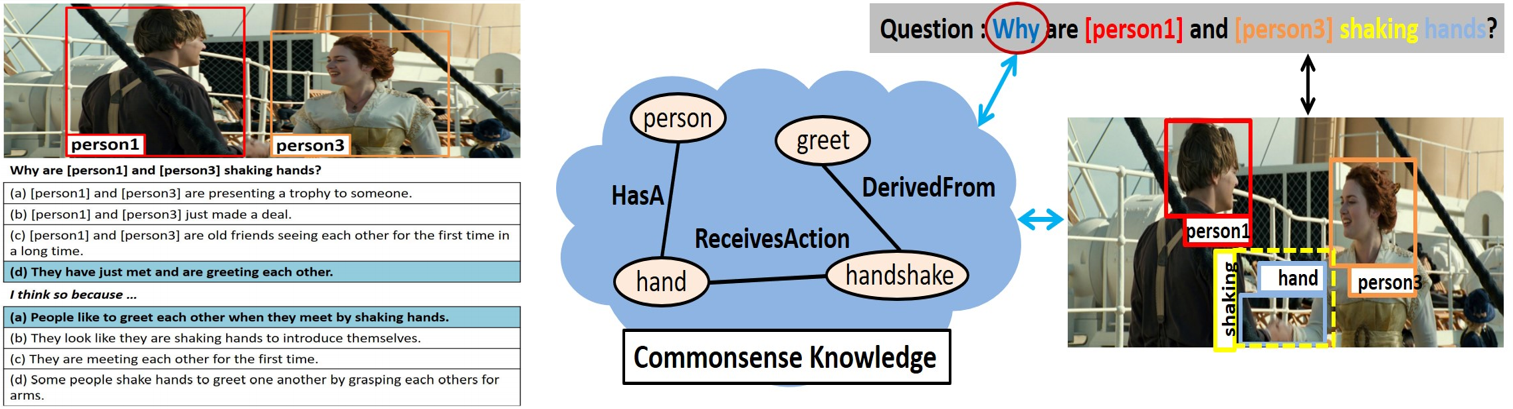
Approach
· 지식 추출단계에서는 입력 정보로부터 얻은 키워드를 Conceptnet에 검색하고, 질문과 유사도 계산을 통해 지식 추출(knowledge extraction)
· 멀티 모달 임베딩(multimodal embedding) 과정에서는 서로 다른 종류의 데이터를 사전 학습한 멀티 헤드 어텐션 (pretrained multi-head attention)
모델을 이용하여 임베딩
· 멀티 모달(multimodal) 모델은 효과적인 임베딩을 위하여 마스킹된 언어 모델링, 마스킹된 영역 분류, 이미지-텍스트-지식 매칭 3가지 작업으로 사전 학습
· 답변 결정 단계에서는 함께 임베딩된 영상, 자연어, 지식 정보로 최종 답변을 예측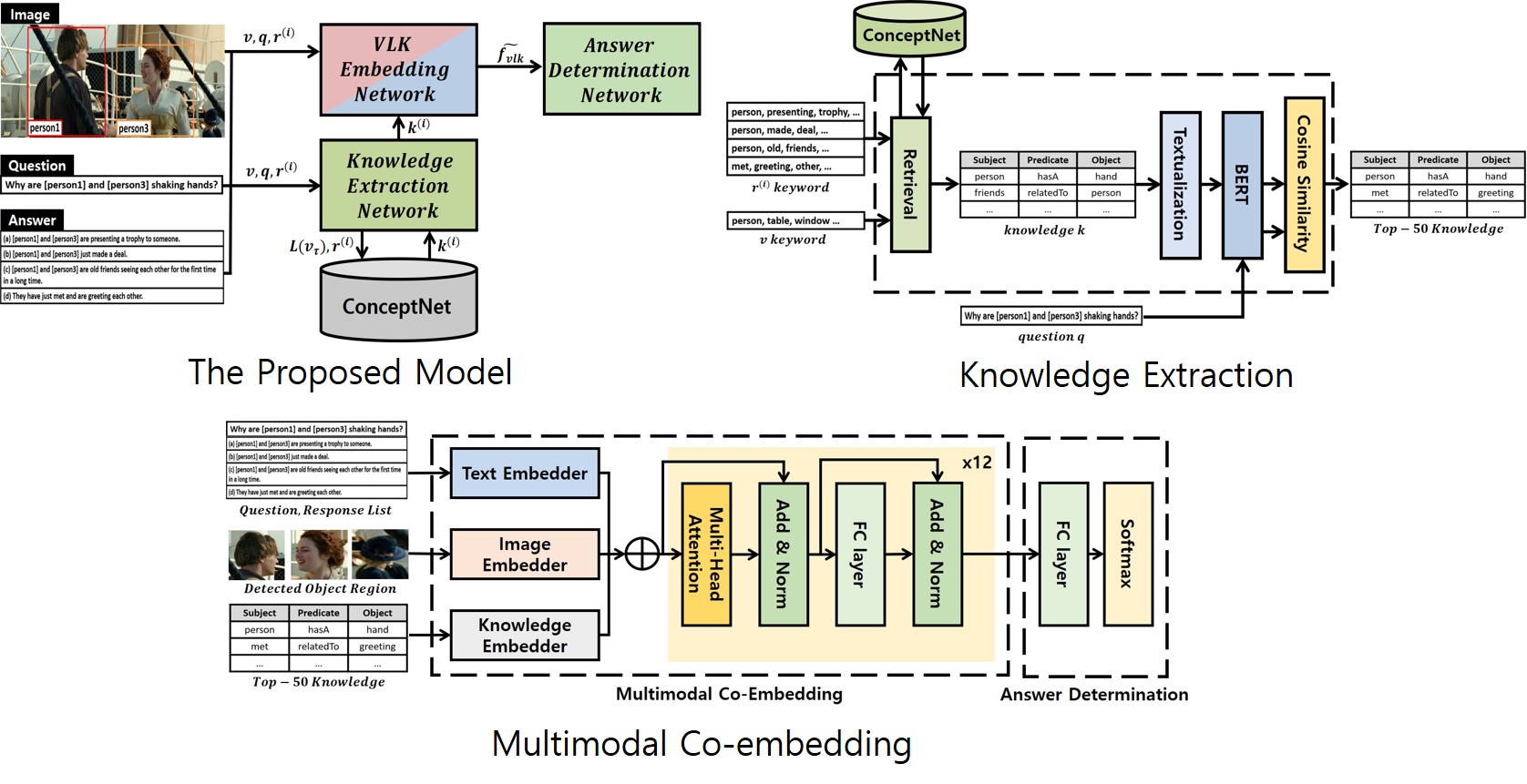
▶ Joint Multi-modal Embedding and Backtracking Search for Vision and Language Navigation(VLN)
Objective
· 시각-언어 이동(VLN)은 가상환경 내에서 자율 에이전트가 자연어 지시와 실시간 입력 영상을 토대로 목적지까지 이동해야 하는 지능 작업
· Matterport3D 시뮬레이터와 R2R(Room-to-Room) 벤치마크 데이터 집합을 모델 학습과 성능 검증에 이용
· 현재 위치 추정 및 지시에 의존적인 행동 결정을 위하여 자연어 지시-입력 영상 간의 상호 정렬(multi-modal alignment)이 요구
· 탐색 성공률(success rate)과 경로 길이 및 시간에 대한 탐색 효율성(search efficiency)을 함께 고려하는 신규 탐색 기법이 요구
· VLN 작업을 위한 효율적인 심층 신경망 모델(deep neural network model) 설계
Approach
· 시각 언어 이동 문제가 갖는 지시-영상 간 상호 정렬 한계성을 해결하기 위한 신규 공동 임베딩 모듈을 제안
· 트랜스포머 기반의 선행학습 공동 임베딩 모듈(pretrained joint multi-modal embedding module) 적용
· 이전까지의 이력을 효율적으로 사용할 수 있는 시간적 맥락화 모듈(temporal contextualizing module) 제안
· 역 추적 및 지역, 전역적 평가가 불가능한 기존 탐색 기법의 한계성을 해결하기 위한 신규 탐색 기법을 제안
· 역추적이 가능한 지역적 탐색(Backtracking enabled Greedy Local Search, BGLS) 알고리즘 제안
· 행동 선택을 위한 지역적 평가 네트워크(local scoring network)와 전역적 평가 네트워크(global scoring network) 설계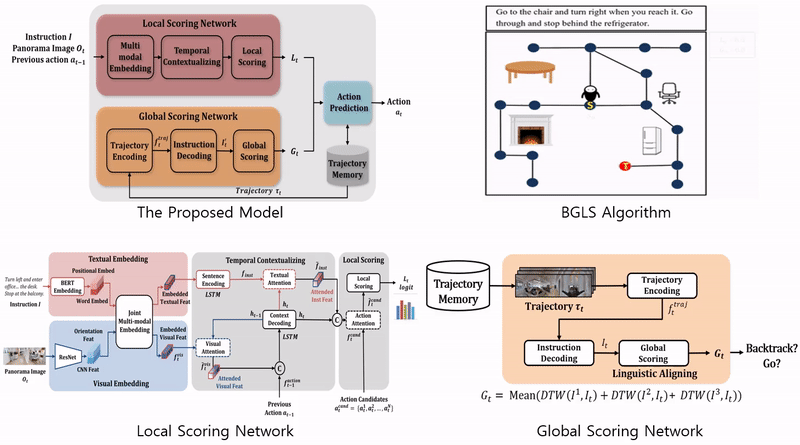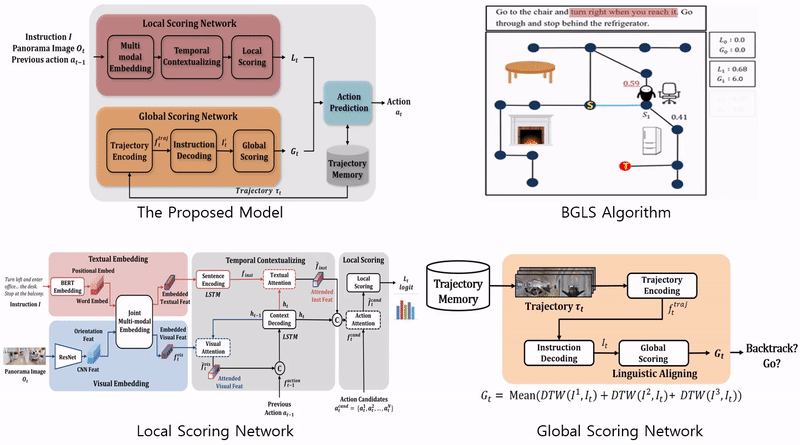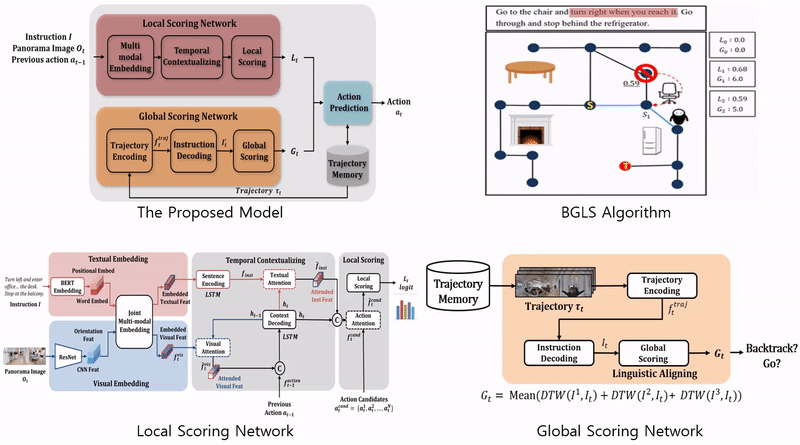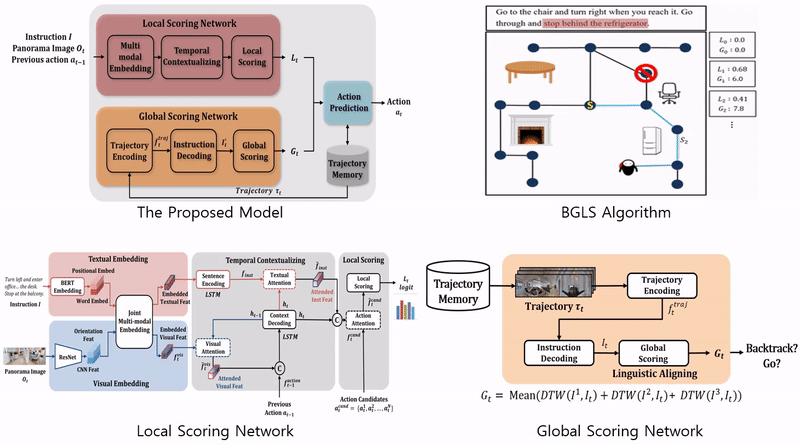
▶ Visual Dialog
Objective
· 영상 기반 대화(Visual Dialog)는 하나의 영상과 그 영상에 관한 설명문을 기반으로 연속적으로 주어지는 질문에 가장 올바른 답변을 생성하는 연구
· 현재 질문과 대화 이력을 기반으로 신경망 모듈들을 동적으로 결합하는 새로운 모듈 신경망(Neural Module Network)를 제안
· 영상 기반 대화가 갖는 시각적 상호 참조 해소 문제를 해결하기 위한 새로운 저장 방식의 참조 풀과 참조 모듈을 제안
· 비교 질문에 효과적으로 대처할 수 있는 비교 모듈, 삼중 주의 집중 메커니즘을 적용한 탐지 모듈을 제안
· 비인칭 대명사 ‘it’을 프로그램 생성 단계에서 별도로 처리하는 방법 제안
· 대규모 벤치마크 데이터 집합인 VisDial v0.9를 이용
Approach
· 프로그램 생성 단계에서는 현재 질문에 적합한 답변을 결정하는데 필요한 모듈들과 그들의 실행 순서를 경정하는 하나의 질문 맞춤형 프로그램 제안
· 프로그램 실행 단계에서는 제안된 프로그램에 따라 각 신경망 모듈들을 동적으로 연결 및 실행
· 답변 디코딩 단계에서는 프로그램 실행 결과인 맥락 벡터를 활용하여 답변 리스트 중 가장 적절한 답변 결정
· 참조 풀 갱신 단계에서는 현재 라운드의 모든 언어를 융합한 특징과 영상에 대한 최종 주의 집중 지도를 참조 풀에 저장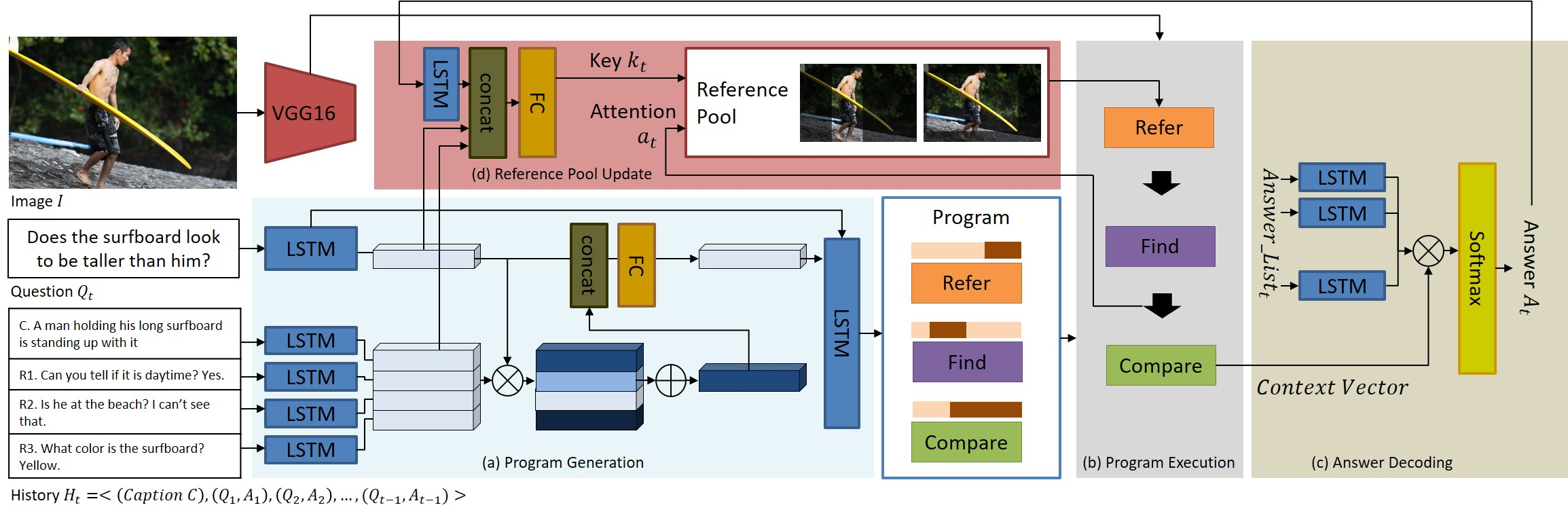
Application

▶ Dynamic Scene Graph Generation from Drama Video
Objective
· 드라마/비디오 주석 데이터 및 장면 그래프 생성을 위한 학습 기술에 관한 연구
· 드라마 ‘미생’의 비디오를 장면 별 등장인물(Character), 발생 장소(Place), 시간대(Timezone), 물체(Object), 행위(Activity), 설명문(Caption)을 인식하는 심층 신경망(Deep Neural Network) 학습 기술 제안
· 인식한 결과와 이를 토대로 한 구조화된 지식 그래프 형태인 장면 그래프(Scene Graph)를 표현할 수 있는 시각화 기술 제안
· 인식 모델들을 위한 학습 및 검증 데이터 집합 생성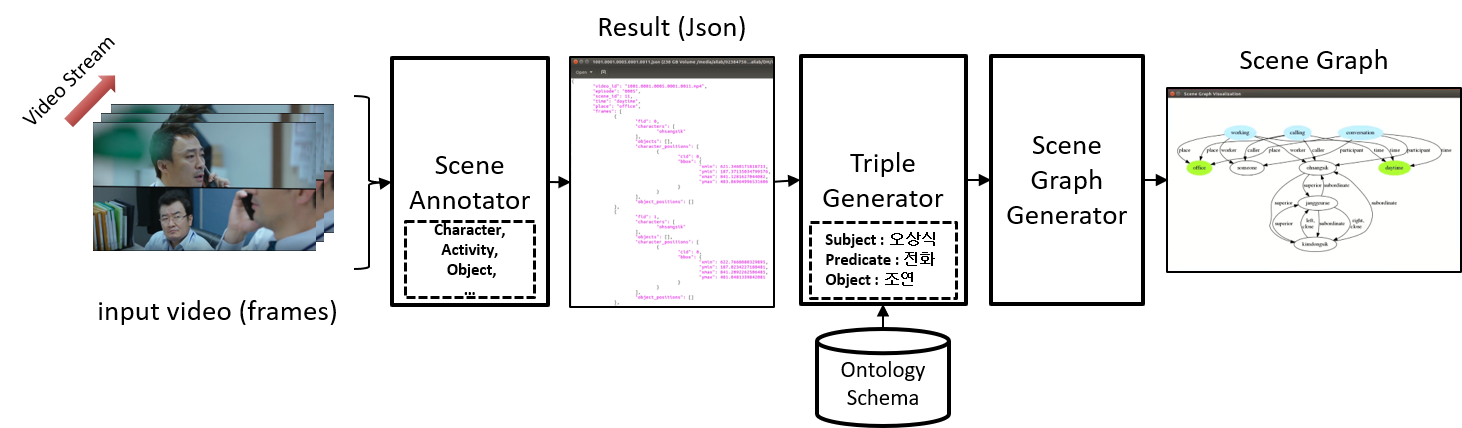
Approach
· 드라마/비디오 주석 데이터를 자동으로 생성하기 위한 Annotation Tool 개발
· 인물 인식 모델은 얼굴 탐지 단계와 얼굴 분류 단계인 두 단계로 나누어 설계
· 장소 & 시간대 인식 모델은 모두 ResNet 모델로 설계
· 물체 탐지 모델은 MS-COCO 데이터 집합으로 사전 학습한 RetinaNet 활용, 검증 데이터로써 미생에서 자주 등장하는 물체 클래스만 사용하여 진행
· 행동 인식 모델은 C3D모델에 LSTM을 적용하여 클립 간 정보 전달 활성화할 수 있도록 설계
· 캡션 생성 모델은 Encoder-Decoder 기반의 LSTM 모델 설계
Application

▶ Dense Video Captioning
Objective
· 비디오를 효과적으로 표현하는 자연어 캡션을 자동으로 생성하는 방법에 관한 연구
· 입력 비디오를 효과적으로 표현하기 위하여 CNN으로부터 추출한 시각 특징(visual feature)뿐만 아니라 고-수준 특징(high-level feature)인 정적/동적 의미 특징(static/dynamic semantic features) 사용을 제안
· 비디오의 예측된 미래 정보까지 이용하여 보다 풍부한 맥락 정보를 활용한 이벤트 시간 영역 탐지 수행
· 학습한 특징을 효과적으로 캡션 생성에 사용하기 위해 주의 집중(attention)과 맥락 게이트(context gating) 기법을 적용한 캡션 생성을 제안
· 대용량 공개 벤치마크 데이터 집합인 ActivityNet Captions 데이터 집합을 이용
Approach
· 의미 특징을 비디오 내의 정적인 속성(물체, 사람, 배경 등)에 해당하는 정적 의미 특징과 비디오 내의 동적인 속성(행위)에 해당하는 동적 의미 특징으로 나누어 학습
· 양방향 LSTM(Bidirectional LSTM, BLSTM)을 통해 얻은 비디오의 예측된 미래 정보를 사용하여 비디오의 맥락정보를 보다 풍부하게 활용, 효과적인 이벤트 시간 영역 탐지 수행
· 시간단계(timestep)마다 현재 생성될 단어와 연관된 의미 특징에 주의집중 가중치(attention weight)를 부여하여 캡션 생성
· 맥락 게이트를 통해 시간 단계마다 입력 비디오 특징과 문맥 정보 중 어느 것이 중요한지 판단하여 캡션 생성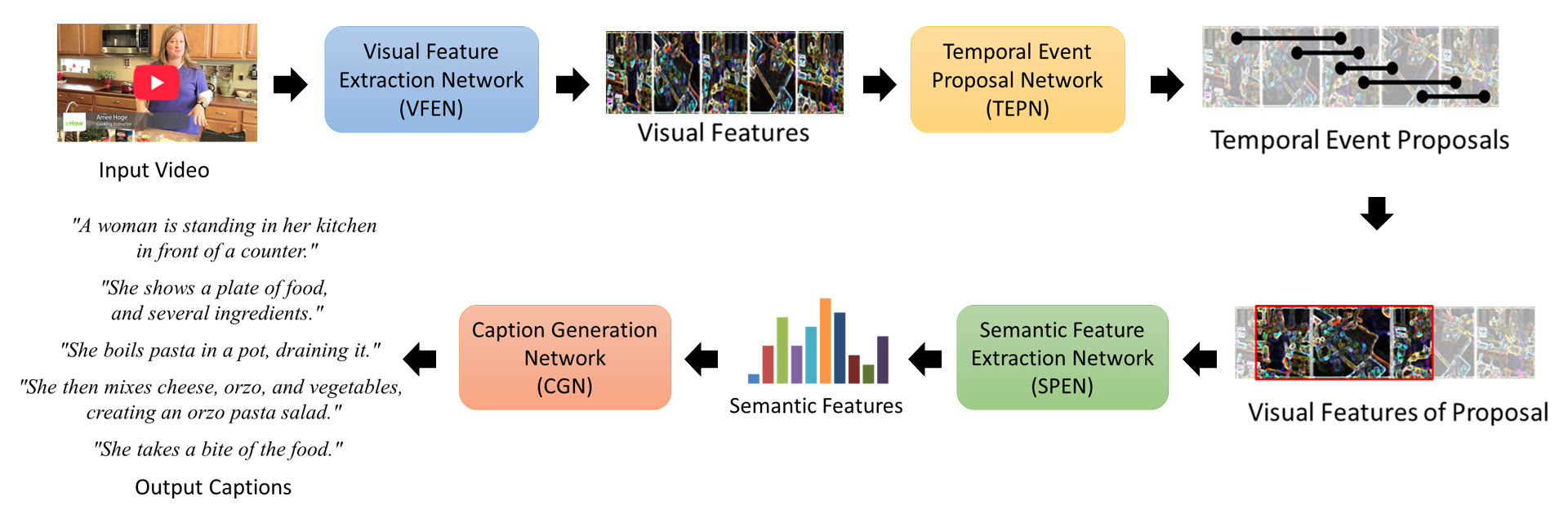
Application

▶ 3D Scene Graph Generation for Visual Experience-based Question Answering
Objective
· 3차원 환경에서 에이전트의 경험에 대한 시각 질문 응답(visual experience-based question answering) 문제 제안
· 3차원 환경에 대한 상태 지식(state knowledge)을 생성하고, 배경 지식 베이스(background knowledge base)와 결합하여 주어진 질문에 대한 답변 생성
· 3차원 장면 그래프(3d scene graph)를 생성하고 상태 지식으로 전환하여 사용
Approach
· 심층 신경망을 이용한 3차원 물체 탐지, 물체 속성 인식, 공간 관계 인식을 통한 3차원 장면 그래프 생성
· 행동 모델(action model)을 통해 행동에 따른 상태 변화 예측
· 심층 신경망을 통해 자연어 문장을 정형화된 질의(formal query)로 변환
· 상태 지식과 배경 지식 베이스를 기반으로, 주어진 질의에 대한 지식 추론(knowledge reasoning)을 수행하여 답변 생성
Application

▶ Activity Detection from Video
Objective
· 비디오 내에서 사람의 행동이 존재하는 영역 탐색(region proposal)과 이 영역 내의 행동을 분류(activity classification)하는 행동 탐지(activity detection)에 관한 연구
· 비디오로부터 각 행동 별 시간적, 공간적 패턴(temporal and spatial pattern)을 잘 표현할 수 있는 멀티 모달 특징(multimodal feature)들을 추출해낼 뿐만 아니라 고수준의 의미적 특징(semantic feature)들을 추출하여 학습에 이용
· 대용량 공개 벤치마크 데이터 집합인 ActivityNet 비디오 데이터를 이용
Approach
· 16 프레임(frame)의 비디오로부터 C3D를 이용하여 시간 특징을 추출하고 ResNet을 이용하여 공간 특징을 추출하는 두 가지 심층 신경망 모델 학습
· 의미적 특징 학습을 위해 앞서 추출된 공간 특징으로부터 각각 동사(verb)와 명사(noun) 특징을 추출하는 두 가지 완전 연결 신경망 모델 학습
· 후보 영역(anchor box)을 이용한 행동 영역 탐지와 분류를 위해 양방향 BI-LSTM을 이용한 두 가지 심층 신경망 모델 학습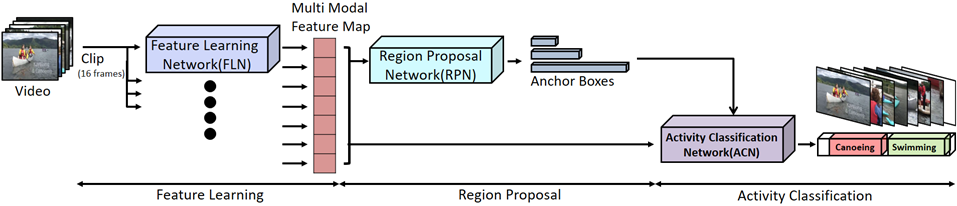
Application

▶ Referring Expression Comprehension
Objective
· 참조 표현(referring expression)이란 주어진 영상에서 특정 물체 영역을 가리키는 문장을 의미
· 참조 표현(referring expression)이 가리키는 영상 내 영역을 찾아내는 방법에 관한 연구
· 영상 처리와 자연어 처리를 병행하는 멀티 모달 처리(multimodal processing)에 관한 연구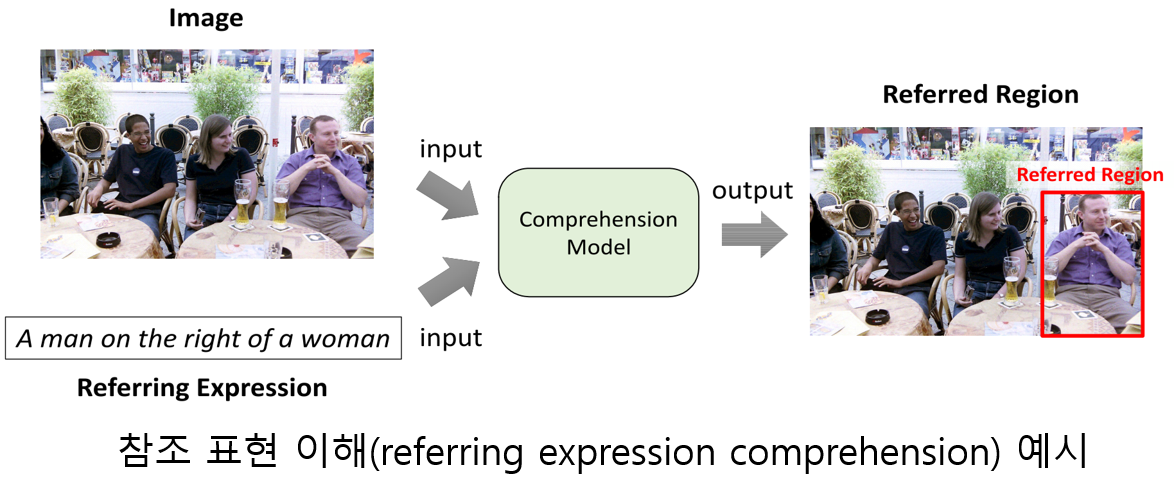
Approach
· 주어진 참조 표현을 대상 영역, 관계, 참조 영역으로 나누어 처리

· 각 부분 표현별로 영상 내 후보 영역들과 비교하여 적합도 판정
· 영상 및 자연어 처리를 위한 CNN, Bidirectional LSTM 사용
· 최적의 성능을 위한 모듈 구조 모델 제시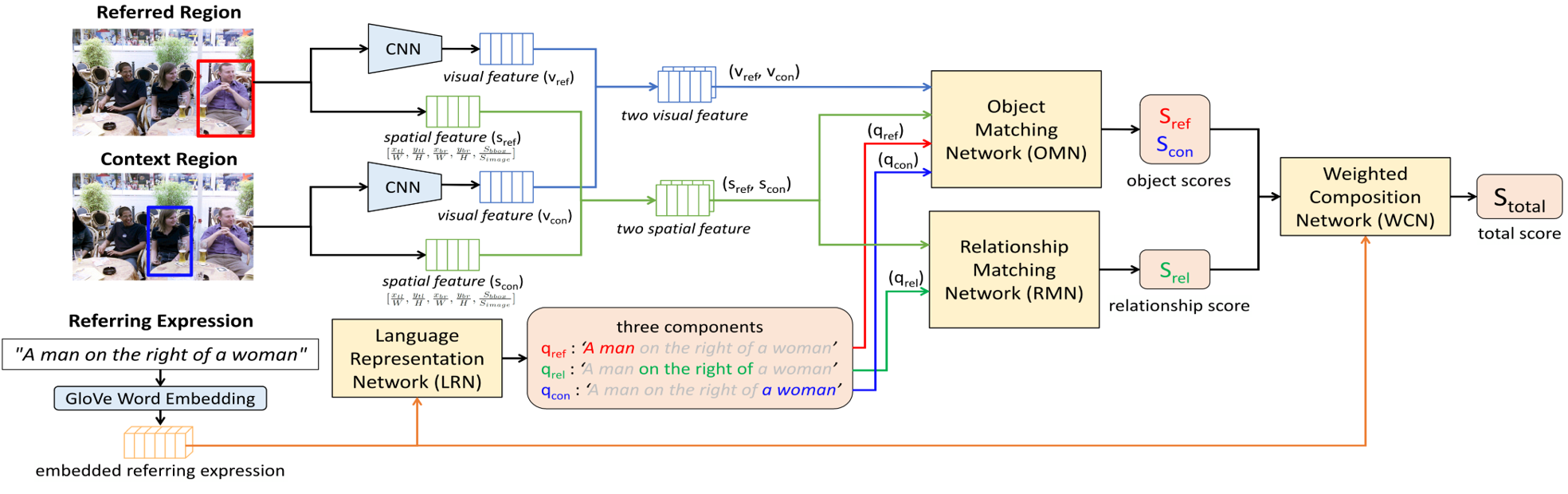
Application

▶ Image Captioning with Deep Neural Networks
Objective
· 효과적인 이미지 캡션 생성(image captioning)을 위해서는 언어 모델과 시각 모델 모두 필요
· 언어 모델(language model)과 시각 모델(visual model)의 효과적인 결합 방식에 관한 연구
· 이미지 캡션 생성에 유리한 순환 신경망 유닛(recurrent unit) 에 관한 연구
Approach
· 멀티 모달 순환 신경망(multimodal recurrent neural network) 모델 제시
· 시각 특징 추출을 위해 고성능의 Inception v3 convolutional neural network을 채택
· 시각 모델과 언어 모델을 결합하는 다양한 네트워크 구조(network structures) 비교와 최적 구조 제시
· 캡션 정확도(caption accuracy)와 모델 전이(model transfer) 면에서 LSTM와 GRU 유닛들의 성능 비교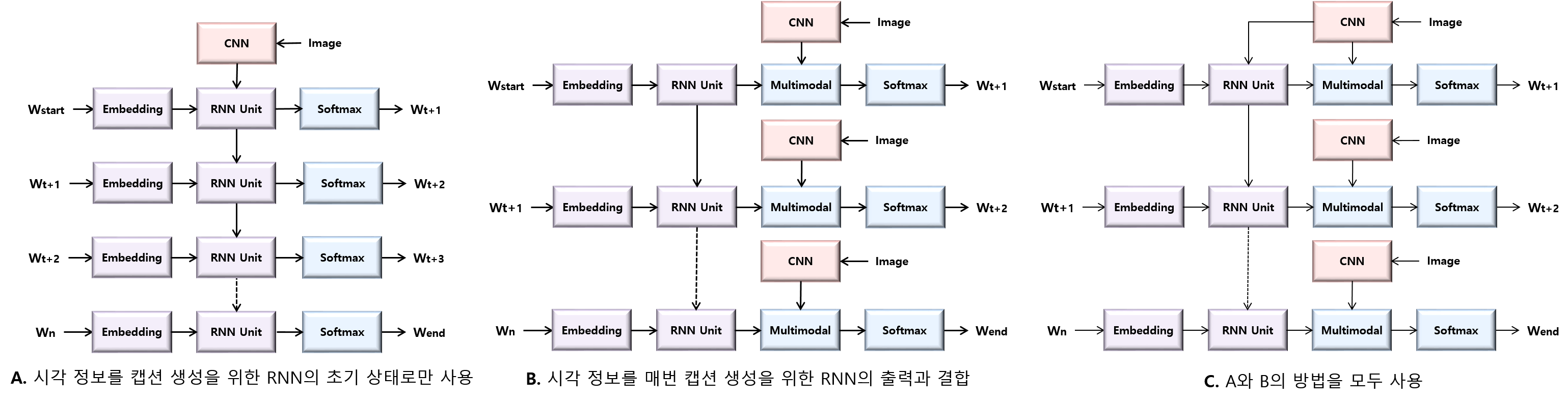
Application

▶ 3D Scene Labeling
Objective
· 2차원 RGB-D 비디오 영상(video images)을 이용하여 포인트 클라우드(point cloud) 형태의 3차원 장면을 복원(3D scene reconstruction)하고, 해당 장면에 포함된 물체들을 탐지하여 레이블링(object labeling)
· 3차원 장면을 구성하는 모든 포인트의 레이블을 결정하기 위해서는 높은 계산 복잡도(high computational complexity) 요구
· 각 포인트의 지역적 특성들(local features)만으로는 정확한 레이블 추정이 어려움. 다양한 문맥적 특성들(contextual features)이 고려되어야 함.
Approach
· 복원된 3차원 포인트 클라우드를 복셀(voxel) 단위로 세그먼테이션(segmentation)
· 각 복셀이 속한 물체 유형(object category)을 추정하여 레이블을 결정
· 확률 그래프 모델(probabilistic graphical model)의 하나인 MRF(Markov Random Field) 을 이용하여 레이블 추정(label estimation)
· 노드 평가(node potential)를 위해 물체 탐지기(object detector)와 3차원 위치 사전 확률 지도(3D location prior map)을 활용
· 에지 평가(edge potential)를 위해 다양한 기하학적 제약들(geometric constraints)을 이용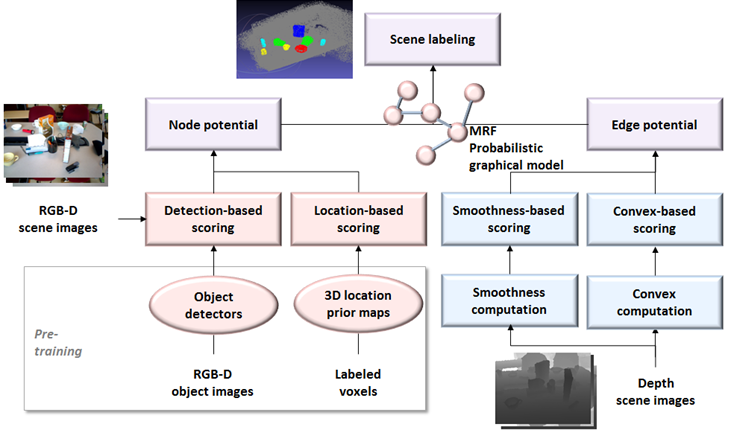
Application

▶ Hierarchical Feature Learning for Object Recognition
Objective
· 컬러(RGB) 영상은 물체의 색상과 텍스처(Texture)정보가 풍부하지만, 기하학적 정보가 부족
· 깊이(Depth) 영상은 물체의 입체적 모양 정보를 직접 표현하지 못함
· 사람이 만든 특징(human-designed feature)들의 일반화 한계
· 범용적으로 이용 가능한 특징 학습 방법 제시
Approach
· 깊이 영상을 전처리(Pre-processing)하여, 모양(shape) 정보 추측에 유리한 법선 벡터(Normal Vectors)로 변환
· 법선 벡터와 컬러 영상을 함께 물체 인식 시스템의 입력으로 사용
· 낮은 레벨(low-level)과 높은 레벨(high-level)의 정보를 모두 활용 가능한 계층적 특징 학습(Hierarachical Feature Learning)을 통해, 물체 인식에 효과적인 특징 자동 추출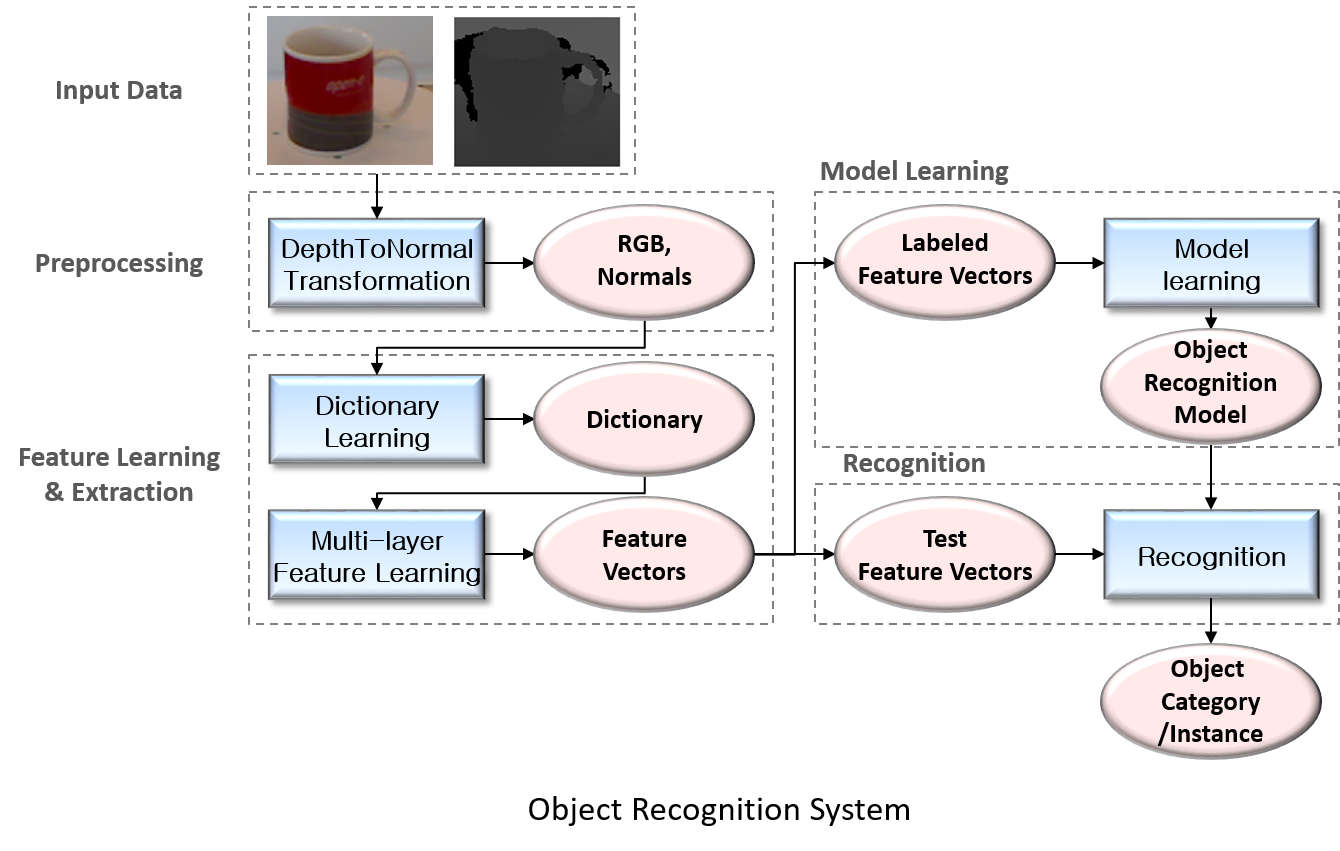
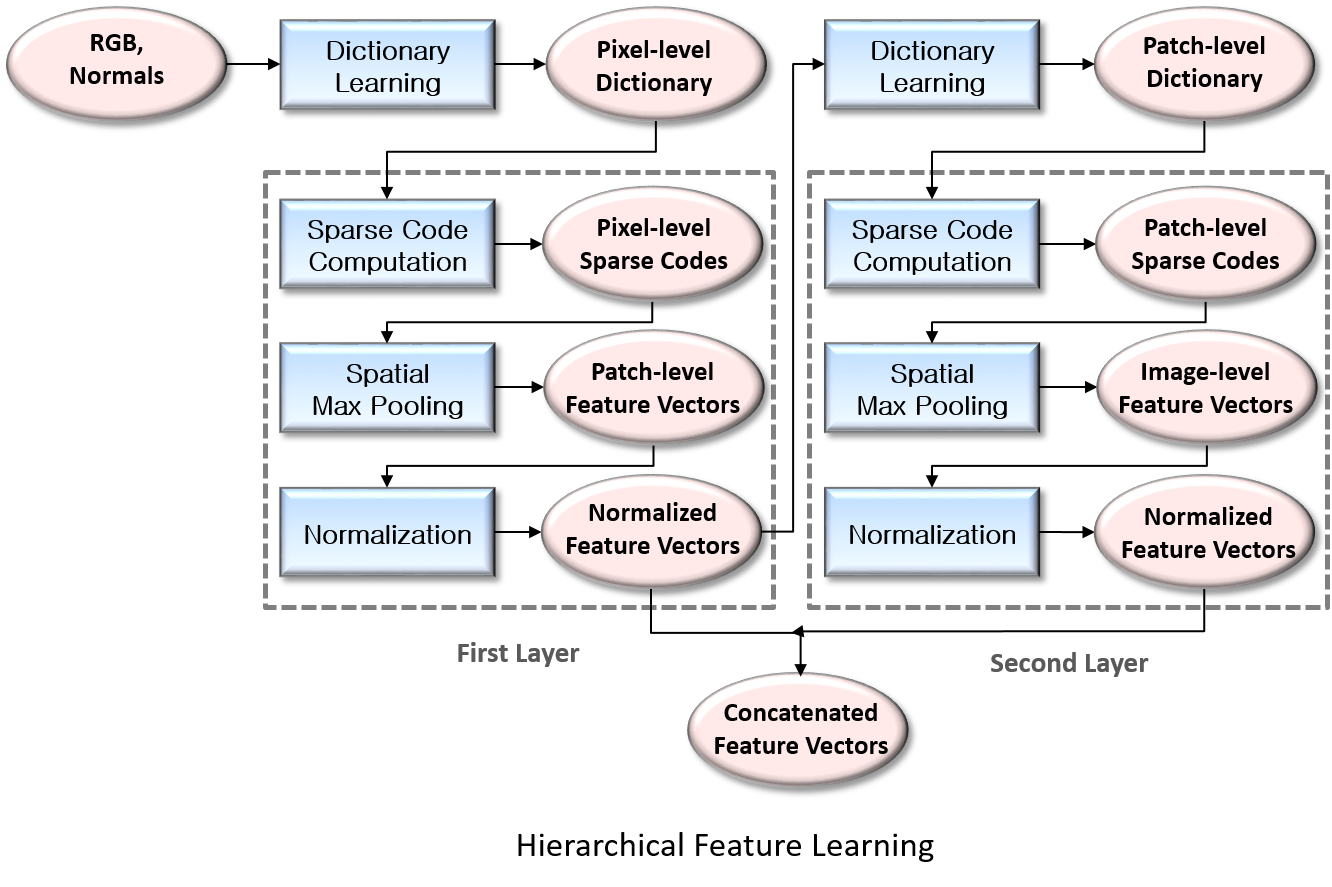
Application

▶ 3D Scene Reconstruction
Objective
· 카메라로부터 입력되는 RGB-D 영상(image)을 기반으로 주행 거리를 측정(odometry)
· 측정된 주행 거리를 최적화(optimization)하여 3D 장면 재구성(scene reconstruction)
· 주행거리의 오차(error)로 인한 드리프트(drift) 발생 문제점
Approach
· 주행 거리 오차를 줄이기 위해 특징을 추출(feature extraction)하고, 추출된 특징 중 정상집합 선별(inlier detection) 및 정제(refine)
· 정제된 정상집합의 재투영 에러 최소화(reprojection error minimization)를 통한 주행거리 측정
· 측정된 주행거리를 최적화하여 3D 장면 재구성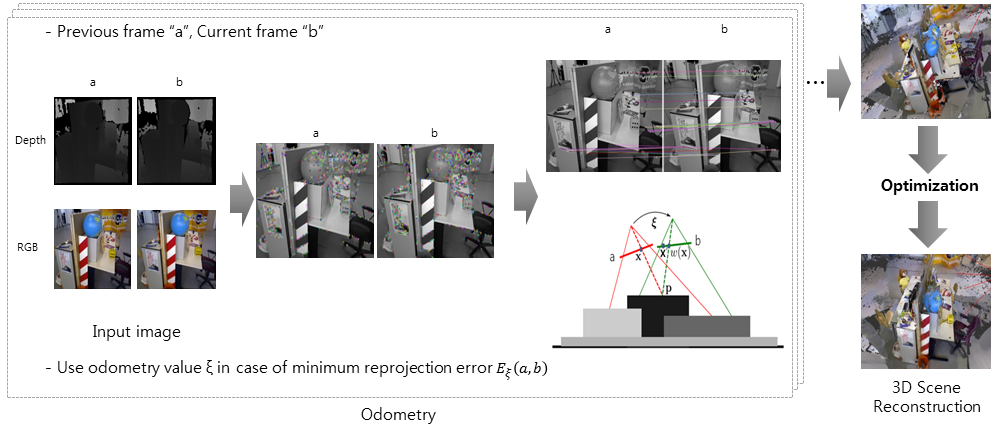
Application

▶ Visual Loop Closure Detection
Objective
· 카메라의 이동 경로 중 과거에 지나온 위치나 장소를 재방문(revisit) 한 지점을 자동으로 탐지
· 방문하는 장소가 증가할수록 루프 결합 탐지(loop closure detection)를 위해 저장되는 영상이 증가
· 저장되는 영상이 증가할수록 영상들 사이의 비교 연산이 증가
Approach
· 카메라의 주행거리(odometry)를 기반으로 키 프레임(key frame) 영상을 선택
· 선택된 키 프레임 영상을 DBoW 이미지 데이터베이스 시스템을 이용하여 저
· 현재 입력된 영상과 데이터베이스에 저장된 영상과의 비교를 통해 루프 결합을 탐지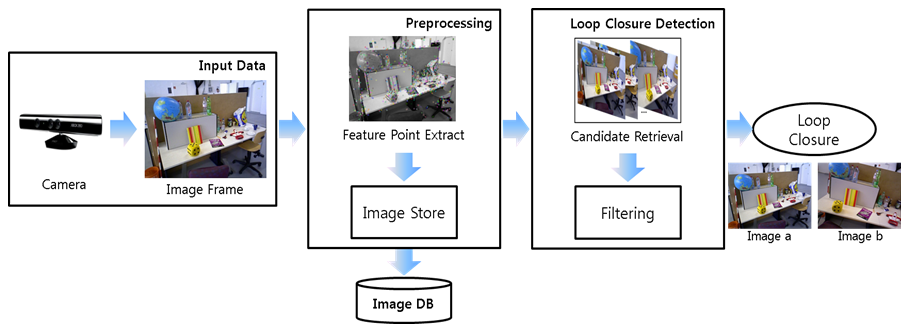
Application

▶ Gesture Recognition with RGB-D Camera
Objective
· 카메라에서 입력된 영상으로부터 실험자의 제스처(gesture)를 판별
· RGB-D 카메라로부터 실험자의 관절 좌표 (joint coordinate) 데이터를 획득
· 관절 좌표 데이터는 추정으로 인한 불확실성,(uncertainty), 시점 변화(view variant), 폐색(occlusion), 자기 폐색(self-occlusion), 조명 여건 등의 문제를 내포함
Approach
· 양 팔의 관절 위치 (joint position) 정보를 이용한 제스처를 인식
· 카메라의 시점 변화 문제를 고려하여 관절의 위치(position) 정보를 각도(angle) 정보로 특징 변환(feature transform)
· 제스처의 시간에 따른 순차성 및 관절 좌표 데이터의 불확실성을 고려하여 확률 그래프 모델(probabilistic graphical model)을 학습 모델로 사용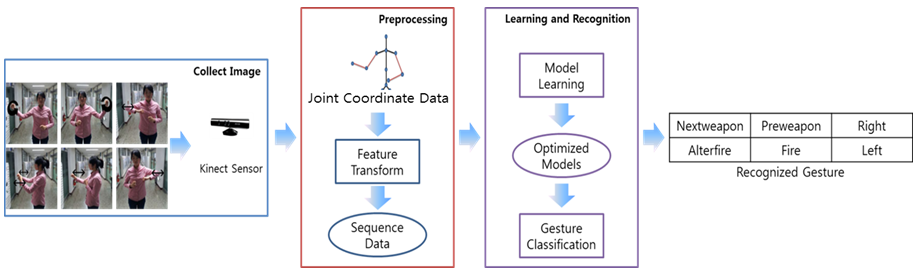
Application

▶ Activity Recognition with RGB-D Camera
Objective
· 관절 좌표(joint coordinate) 데이터로부터 실험자의 일상 행위를 인식하는 기술
· RGB-D 카메라에서 추정된 관절 좌표 데이터는 추정의 불확실성(uncertainty), 시점 변화(view variant), 크기 변화(scale variant), 자기 폐색(self-occlusion)의 변화 등의 문제를 내포함
· 일상 생활에서 수행되는 행위들은 여러 개의 부속 행위(sub-activity)들의 반복으로 구성됨
Approach
· 관절 좌표 데이터가 가지는 시점 변화 문제를 해결하기 위해, 구면좌표계(spherical coordinate system)를 이용
· 관절 좌표 데이터가 가지는 크기 변화 문제를 해결하기 위해, 크기 정규화(scale normalization)을 적용
· 일상 행위들이 가지는 계층성(hierarchical)과 순차성(sequential)을 고려하여 모델 학습에 확률 그래프 모델(probabilistic graphical model) 사용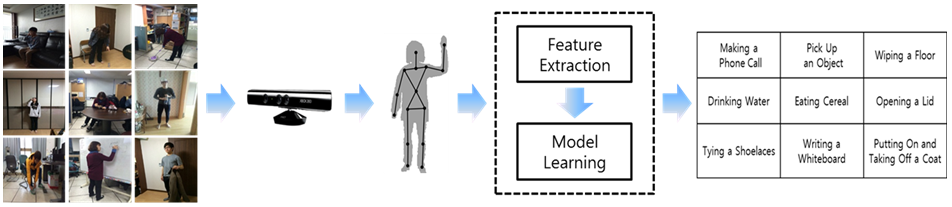
Application
